After my two previous posts discussing dictionary lookups in JavaScript and JavaScript Trie performance analysis even more excellent feedback came in from everyone.
Out of all the results two techniques seemed to be most interesting – and promising for reducing general memory usage and load time.
String-based Binary Search
The first technique proposed was left as a comment by a commenter named Randall. He utilized a technique posited by Mathias Nater to create a smaller dictionary and search the results using a binary search.
The technique breaks down into two parts: The smaller dictionary and the binary search.
The smaller dictionary is achieved by taking the regular dictionary and grouping the words by length. Thus you’ll end up with clusters of words that are all equal lengths. For example:
[ "catdoghat", // all length 3 "foodridewood", // all length 4 ... etc. ]
If all the words in a particular string are the same length then it makes it quite easy to jump around inside it (you just always move forwards or backwards in the string one word’s length). This reduces the resulting, uncompressed, file size of the dictionary by about 110,000 bytes (there is now one less space for each word in the dictionary).
Having the words of uniform length makes it easy to implement a binary search. The code written by Randall is rather simple and effective:
function findBinaryWord( word ) {
// Figure out which bin we’re going to search
var l = word.length;
// Don’t search if there’s nothing to look through
if ( !dict[l] ) {
return false;
}
// Get the number of words in the dictionary bin
var words = dict[l].length / l,
// The low point from where we’re starting the binary search
low = 0,
// The max high point
high = words – 1,
// And the precise middle of the search
mid = Math.floor( words / 2 );
// We continue to look until we reach a final word
while ( high >= low ) {
// Grab the word at our current position
var found = dict[l].substr( l * mid, l );
// If we’ve found the word, stop now
if ( word === found ) {
return true;
}
// Otherwise, compare
// If we’re too high, move lower
if ( word < found ) {
high = mid - 1;
// If we're too low, go higher
} else {
low = mid + 1;
}
// And find the new search point
mid = Math.floor( (low + high) / 2 );
}
// Nothing was found
return false;
}[/js]
Doing a binary search will almost certainly yield a faster result compared to a simple linear search through the string (such as doing a .indexOf).
Trie Stored in a Succinct Data Structure
The other solution that popped up was proposed by Steve Hanov. His solution was to continue utilizing the Trie structure but store it in a succinct data structure. He explains it extremely well so I would highly recommend visiting his blog to get the full details of the solution.
In short all the leaves of the Trie are given a number and stored in a table (resulting in a data structure for lookups and a data structure for the actual data itself). Additionally he went a step further and encoded all the data using Base 64 and modified the algorithm to utilize that encoding – thus all the encoded data can remain as a string and never have to be turned into a large JavaScript data structure.
Ideally this solution will provide a much smaller file size and memory usage.
File Size Analysis
We still want to make sure that the file size of the dictionary isn’t too large – saving us some potential bandwidth costs. Digging in to the file size results yields some very interesting data.
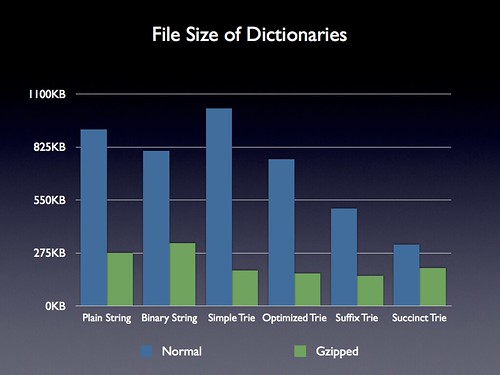
Unsurprisingly the uncompressed binary string is smaller than the plain string – but quite surprisingly the final gzipped size actually ends up being larger than the original. I can only assume that the spacing in the original ended up helping the gzip algorithm compress the resulting text easier – definitely not an intuitive result, though.
Additionally when we look at the results for the succinct Trie we do see that it’s uncompressed file size is quite small (only about 300KB). Amusingly, its compressed file size ends up being larger than any of the previous Trie structures – but still smaller than the regular strings.
If we were only concerned with file size then the suffix optimized Trie would still be the way to go.
Load Speed Analysis
As with before, analyzing the initial load speed of the dictionary ends up being crucial. If we’re utilizing a JavaScript object we have to evaluate it first – and that can end up taking a considerable amount of time.
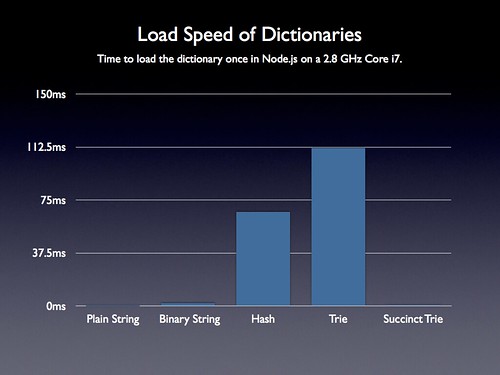
Thankfully both of the new techniques load virtually instantaneously (taking only 0.65 – 1.7ms to load the whole dictionary, which makes sense, since they’re both coming from simple strings and require no code evaluation).
Search Speed Analysis
As I mentioned in my last post, the performance of word lookups wasn’t nearly as important in my particular use case as all the other considerations. Having a lookup take a couple milliseconds was OK since they were only going to occur every couple seconds or so. This may not be the case for every application – and I still wanted to make sure that the code wasn’t going to take any major performance hits.
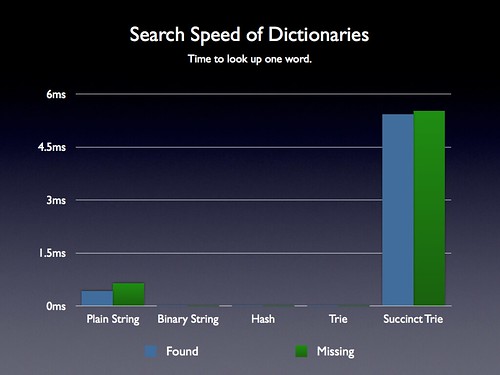
The binary string search ends up being quite fast – even faster than the old Trie search, which is quite promising. However the new Succinct Trie ends up being disturbingly slow (taking about 5.5ms to look up a word in Node.js on a fast machine). I double-checked and the lookup time for finding a word on an iPhone 4 using iOS 4.3 is about 46ms. Even taking that into account I think that’s still a lookup rate that I can live with in my particular application. However it most certainly will be too slow for many situations (and in those cases they’ll likely want to use the Binary String technique).
It’s not clear to me how much of the Succinct Trie’s performance stems from its implementation. Perhaps there could be some improvements made to it to increase its final word search time.
Memory Usage Analysis
I finally revisited memory usage, as well. This continues to be critical on mobile devices. Using too much memory will cause all sorts of problems and frequently force the browser to reload your application.

The Binary String technique does well. Being a simple string (and of a smaller total size) means that it uses less memory as well. However the Succinct Trie technique does absolutely stellar – as it’s a string as well, and since it’s total uncompressed size is only about 1/3 of a MB, that’s all the memory that it ends up using. This is fantastic and certainly a huge encouragement towards using this technique.
Conclusion
Even though it’s not quite as small (compressed file-size-wise) as a regular Trie and even though its lookup speed is significantly slower than any other technique (but still usable) – I’m heavily inclined to use the Succinctly Stored Trie Structure. I would definitely like to encourage everyone to look at this particular technique further as, currently, it provides excellent memory usage, reasonably-small file size, and virtually non-existent startup overhead. If you’re OK with having relatively slow word lookups then this is certainly the technique for you.
If slow lookup speed is undesirable then I would be inclined to use the binary string search technique (as it still provides decent memory usage, reasonable file size, and reasonable memory usage).
As always, all the code and tests are up on Github:
https://github.com/jeresig/trie-js
Raw Data
The raw data for the updated tests (which can be found in my Trie.js Github repo) are as follows:
Binary String -------------- Normal: 806KB Gzipped: 326KB Build Speed: 174 (1.74ms per) Find Speed: 369 (0.0033ms per) Not Find Speed: 197 (0.0012ms per) Private Memory: 112.2MB (0.98MB per) Succinct Trie -------------- Normal: 317KB Gzipped: 197KB Build Speed: 65 (0.65ms per) Find Speed: 609985 (5.43ms per) Not Find Speed: 622700 (5.54ms per) Private Memory: 47.1MB (0.33MB per)


Josh (March 22, 2011 at 9:02 pm)
Why not just lazy-load the dictionary in the format best optimized for search speed and memory usage? Why privilege initial load time unless you have to? Must be missing something….
John Resig (March 22, 2011 at 10:12 pm)
@Josh: I think you may have missed the previous posts – the “load” is a unchangeable amount of time that the browser takes to process the text into a form that is usable (in the case of the Trie that means evaluating it into a JavaScript object – in the case of the Succinct Trie that means doing a string split). You can’t really lazy load that operation as it’ll block the browser in any way that you do it (I’m not talking about the download time, that’s something else entirely and dependent upon the file size).
— and even so, the best solution for memory usage is still the Succinct Trie so it still serves as the best available option, regardless of its initial load time (and its load time is very fast).
Terry Riegel (March 22, 2011 at 10:29 pm)
John,
I have enjoyed this and the other 2 posts.
Steve Hanov (March 22, 2011 at 10:35 pm)
Hi, John! Thanks for trying out the succinct technique. The results are surprising. The main performance problem with my code is the ORD function which should be changed to use a table. The lookup then runs at least two to three times as fast.
/**
Returns the decimal value of the given character unit.
*/
var BASE64_INDEX = {};
for ( var i = 0; i < BASE64.length; i++ ) {
BASE64_INDEX[BASE64[i]] = i;
}
function ORD(ch)
{
//return BASE64.indexOf(ch);
return BASE64_INDEX[ch];
}
Jason Persampieri (March 22, 2011 at 11:00 pm)
I, too, have found this series quite fascinating. Always good to revisit “don’t optimize prematurely”, with the corollary, “optimize the *system*, not a single code path”.
Also, Steve, your blog is similarly excellent…. added!
Mike Koss (March 22, 2011 at 11:31 pm)
I just noticed you moved on to a 3rd post on this topic. I did update the Trie/DAWG solution and managed to get a pre-zipped 180K file size for the large dictionary.
http://lookups.pageforest.com
I haven’t done the lookup benchmarks to compare, but I’m pretty sure the PackedTrie lookup will be blazingly fast given the very simple operations it has to perform on the in-memory structure.
I’d be interested to know how you think it stacks up against the other alternatives you’ve analyzed.
– Mike
John Resig (March 22, 2011 at 11:33 pm)
@Steve: Great suggestion Steve! I took it a step further and simply replaced the ORD function with the object itself.
https://github.com/jeresig/trie-js/commit/759adc928b77025348b7a1a9ae688c3047eb7c21
I’m now seeing lookups being done in about 3.6ms – which is still slow, but a solid 2ms improvement!
@Terry, Jason: Glad you’ve been enjoying the blog posts! :)
@Mike: I definitely plan on analyzing your solution as well, it looks terribly promising!
John Resig (March 22, 2011 at 11:42 pm)
@Mike: I just took a quick pass with my dictionary through your script and I’m seeing 244KB uncompressed, 155KB compressed – making it the smallest solution so far. I will investigate further once I’ve gotten some sleep.
Steve Hanov (March 23, 2011 at 12:11 am)
@Mike: I have been following your work with great interest. As dictionary size increases, a compact DAWG might be the way to go. It will be interesting to see how splitting the string will impact memory consumption. Perhaps your method could benefit from my BinaryString/BitWriter BASE-64 functions, so you can store pointers to each node more compactly, as offsets into the string.
Stephen Jones (March 23, 2011 at 12:37 am)
Here’s a possible way to make your binary search dictionary smaller and faster:
Split your size-grouped words into 26 separate arrays, one for each starting letter. Then, leave off the shared letter of each word in each list.
Example:
[ "aceaidaskcabcancarcat", "ableablyaltocapecamecare" ]
would become
a: [ "ceidsk", "bleblylto" ]
c: [ "abanarat", "apeameare" ]
Not only will this save you 100K or so (one character per word minus overhead) but would also speed searches greatly because words starting with ‘r’ will only have to binary search within the ‘r’ list, etc.
Anthony Molinaro (March 23, 2011 at 1:03 am)
I’m not so sure about the implementation on pageforest. I loaded the dictionary and built the trie then did a lookup for ‘battle’ completely randomly and it’s not in the trie (but it is in the dictionary if I scroll down to find it). Just makes me think you might want to do some sanity checks (heck you might want to take every word in the original dictionary and make sure it’s in the trie or other data structure). Probably just a subtle bug which I got lucky and hit because I haven’t yet found another word in the dictionary list which isn’t in the trie.
Great set of blog posts BTW.
Horia Dragomir (March 23, 2011 at 2:14 am)
It’s nice to see Computer Science used in web development, for sure.
Most web developers would squint if you asked them about Big O.
R (March 23, 2011 at 2:15 am)
Succinct tree is truly impressive stuff. Thanks for the shout-out and for cleaning up and commenting the rough binsearch-through-a-string code. :)
Rhys (March 23, 2011 at 4:29 am)
Would it improve the binary string further if, within each group, the words were sorted alphabetically, so then you could start searching from, for example for a word beginning with k, 11/26 the way along the dictionary and then work backwards/forwards depending on whether the word at that position comes after or before your search term when compared alphabetically.
Philip Fitzsimons (March 23, 2011 at 5:38 am)
does this solution have the classic binary search bug:
// And find the new search point
mid = Math.floor( (low + high) / 2 );
will still overflow or be infinity in some edge cases I think (IMHO), maybe this would avoid:
int mid = low + ((high – low) / 2);
this was the bug identified by Job Bently’s Programming Perls see also http://googleresearch.blogspot.com/2006/06/extra-extra-read-all-about-it-nearly.html
of course you probably won’t see these given your dataset size ;-)
Andrew Barry (March 23, 2011 at 8:27 am)
Just for fun I knocked together a simple inline trie encoding, using some of the concepts in a comment by Emmanuel Briot in the original article.
AAH!ed!ing!s!L”II!s!s#RDVARK”s!wolf%gh”RGH!h!S%VOGEL!s!BA(CA!s!i”k!US!es!ft$KA!s!LONE#s!
is the encoding for:
aah aahed aahing aahs aal aalii aaliis aals aardvark aardvarks aardwolf aargh aarrgh aarrghh aas aasvogel aasvogels aba abaca abacas abaci aback abacus abacuses abaft abaka abakas abalone abalones
1. Uppercase characters are collected as part of a the new prefix
2. Lowercase characters are just part of the current word
3. A word is terminated with a single character from ‘!’ up to (but not including) ‘A’ – each character above ‘!’ indicates the number of prefix characters to drop from the prior prefix
The 938K word list encodes down to 340K which gzips down to 156K.
The nice thing about this approach is that it is competitive size-wise with the succinct trie (7% larger decompressed, but 20% smaller over the wire), while being drastically simpler.
Main disadvantage is the lack of indexing – checking for a word potentially needs to decode the entire string, but this is simply optimized by slicing the string into the subsequences -ie:
{ a: “AAH!ed!ing!s!L”II!s!s#…”,
b: “BAA!ed!ing!L!Im!SM!s!s$S”…”,
… }
John Resig (March 23, 2011 at 9:52 am)
@Anthony: Hmm, you’re right – I can confirm that bug. Mike, I saw that you have some tests for your code, perhaps this is something that slipped through? (Doing some quick testing showed that battle, battles, battled, and batten all fail.)
@Stephen, Rhys: There absolutely are improvements that could be made to the binary search – although they’re mostly moot since it seems like the other Trie-based techniques yield much better memory-usage qualities (and the lookup performance is already “good enough” to not really work about further optimization).
Mike Koss (March 23, 2011 at 10:58 am)
@Anthony @John – Oops! Quite right. There is a bug in my implementation – it’s in the building of the Trie/Dawg – not in the decoder as far as I can tell now. I’m looking into this now. (Good idea, Anthony, to run put a large portion of the dictionary words in my unit tests – I’ll do that too).
Mike Koss (March 23, 2011 at 11:52 am)
@Anthony @John – I found (and fixed it). Embarrassingly, I had an off-by-one in ALL the symbol references – my manual testing never hit any of those cases. I’ll be updating the unit tests now to make sure the generated symbols get tested (this is a harded test to write as you need a pretty large dictionary source before you need to start generating symbols).
Thanks for finding the bug!
Taliesin Beynon (March 23, 2011 at 1:06 pm)
Those time and memory graphs could do with being on a log vertical scale — you’re throwing away most of the information otherwise because the differences between these algorithms often span multiple orders of magnitude.
Mike Koss (March 23, 2011 at 1:27 pm)
New Unit Tests in place. Passes on a random sample of 1% of words in the ospd3 dictionary (Whew!). I also added a timing result (in console.log).
http://lookups.pageforest.com/test/test-runner.html
On my iMac/Chrome a lookup takes:
80 us (microseconds) on a Trie lookup
45 us on a PackedTrie lookup
This seems counter intuitive to me that the PackedTrie lookup code could be faster than the in-memory JavaScript objects based lookup. I’ll have to give this some thought or do more detailed benchmarks of the code to see if this is really true.
R (March 23, 2011 at 1:58 pm)
Devious idea: keep most of the dictionary in localStorage and only pull out the part you need to look up a given word (slicing it up by, say, first letter). Seems to be compatible with most any dictionary approach.
One problem with that is how long it initially takes to put things into localStorage — it looks like at least 1ms per key. At the cost of complicating your app, you could save the dict one key at a time in the background with a timer, and use a dict in memory (or on a server) until it’s all saved. You still probably take the full memory hit on the first page load, just less afterwards.
Another problem with it is that while it lowers the “official” heap size in Web Inspector, I haven’t tested if there’s some hidden cost that kills the practical benefits (i.e., if it really is any less likely to get the tab reloaded in iOS Safari). I don’t think it’s a viable choice when the succinct trie is this good and more “pure” and may have more room for tuning, but thought it was worth mentioning.
(Bit twiddling in JS seems pretty fun. I wonder about String.charCodeAt + arithmetic as a substitute for a lookup table. I should quit spewing ideas and write something, of course. :) )
@Philip: yes, I have the classic binary search bug — though if the dataset you’re searching is *that* big, file size is gonna be a problem. :)
Mike Koss (March 24, 2011 at 8:54 pm)
I built some perf tests for the Trie and PackedTrie code. You can run it (and record the results to my server) by visiting:
http://lookups.pageforest.com/test/perf-test.html
Thanks,
Mike
Mike Koss (March 25, 2011 at 2:58 pm)
One more update. I added the following API to the PackedTrie class:
words(string) – returns all dictionary words with string as a prefix
match(string) – returns the largest matching prefix from the dictionary
A demo of getting 100 words from a prefix is now on:
http://lookups.pageforest.com
Enjoy!
Mike