After my last post discussing dictionary lookups in JavaScript the unanimous consensus seemed to be that utilizing Trie would result in additional space savings and yield performance benefits.
A Trie is a relatively simple data structure. At its simplest form you’re building a tree-like structure where each final leaf results in a complete word. This allows for some very efficient use of file size – reducing common prefixes in words quite easily.

I looked through a number of JavaScript Trie solutions and yet was not terribly pleased with them. They were either total overkill (including large object structures and functionality far beyond what I needed) or weren’t compressing the resulting data structure enough. The closest in functionality that I found, to what I wanted, was what was written by Henrik Hinrichs, called wordlistparser. Wordlistparser creates a simple Trie structure using Node.js.
I’ve dumped my work-in-progress JavaScript Trie Generator up on Github (note that it requires Node.js to run).
Generating a Trie
The basic Trie generation functionality is as follows (note that I use ‘0’ or ‘$:0’ to indicate a complete word):
// Go through all the words in the dictionary
for ( var i = 0, l = words.length; i < l; i++ ) {
// Get all the letters that we need
var word = words[i], letters = word.split(""), cur = trie;
// Loop through the letters
for ( var j = 0; j < letters.length; j++ ) {
var letter = letters[j], pos = cur[ letter ];
// If nothing exists for this letter, create a leaf
if ( pos == null ) {
// If it's the end of the word, set a 0,
// otherwise make an object so we can continue
cur = cur[ letter ] = j === letters.length - 1 ? 0 : {};
// If a final leaf already exists we need to turn it
// into an object to continue traversing
} else if ( pos === 0 ) {
cur = cur[ letter ] = { $: 0 };
// Otherwise there is nothing to be set, so continue on
} else {
cur = cur[ letter ];
}
}
}[/js]
<strong>Optimizing the Structure</strong>
While this is fine I wanted to go a step further. Rather than having single letters at every leaf of the tree I saw much room for optimization. <a href="https://johnresig.com/blog/dictionary-lookups-in-javascript/#comment-392044">Dave Ward posted</a> a sample tree structure which was rather similar to what was generated by Henrik's code (only Henrik's code used '$:1' instead of 'end:true' to save bytes). Looking at the resulting tree structure provided by Dave I was not terribly pleased with the resulting number of objects or code length.
<strong>Code posted by Dave Ward</strong>
[js]var trie = {
b: {
a: {
r: {
end: true,
s: {
end: true
}
}
}
},
f: {
o: {
o: {
end: true
}
}
},
r: {
a: {
t: {
end: true,
e: {
end: true
}
}
}
}
};
I saw that letters that only had a single child could be reduced into a single string. “r a t” could just become “rat”. Additionally there was no need to have a bulky {$:1} structure just to denote the end of a word when you could just use the number 1 to indicate that as well.
Possible Optimization
var trie = {
bar: {
$: 1,
s: 1
},
foo: 1,
rat: {
$: 1,
e: 1
}
};
This change compresses the structure of the Trie down to its bare minimum – using only 3 object literals instead of the previous 12. Using the particular Trie structure makes lookups slightly more challenging (you need to look at the entire start of the word string, rather than just the first character) but it still seems to perform well enough.
The code for optimization:
// Optimize a Trie structure
function optimize( cur ) {
var num = 0;
// Go through all the leaves in this branch
for ( var node in cur ) {
// If the leaf has children
if ( typeof cur[ node ] === "object" ) {
// Continue the optimization even deeper
var ret = optimize( cur[ node ] );
// The child leaf only had one child
// and was "compressed" as a result
if ( ret ) {
// Thus remove the current leaf
delete cur[ node ];
// Remember the new name
node = node + ret.name;
// And replace it with the revised one
cur[ node ] = ret.value;
}
}
// Keep track of how many leaf nodes there are
num++;
}
// If only one leaf is present, compress it
if ( num === 1 ) {
return { name: node, value: cur[ node ] };
}
}
There’s still room for some additional improvement, though. I looked at the changes proposed by the directed acyclic word graph and realized that there was a minor tweak that could be made for improving file size even more: Reducing the number of common suffixes.
For example if you had the following words: sliced, slicer, slices, diced, dicer, dices – you would note that they have common endings (d, r, s) that could be reduced. I added another simple improvement to my Trie implementation that took this into account.
var trie = {
slice: 1,
dice: 1,
$: [ 0, { d: 0, r: 0, s: 0 } ]
};
While it’s not as impressive with only two root words – it ends up working surprisingly well when you have over 100,000 words, reducing file size even more. The full code for finding, and reducing, the common suffixes can be found on Github.
Finding a Word
To find a word in the Trie it requires a little more work than the traditional Trie search:
function findTrieWord( word, cur ) {
// Get the root to start from
cur = cur || dict;
// Go through every leaf
for ( var node in cur ) {
// If the start of the word matches the leaf
if ( word.indexOf( node ) === 0 ) {
// If it's a number
var val = typeof cur[ node ] === "number" && cur[ node ] ?
// Substitute in the removed suffix object
dict.$[ cur[ node ] ] :
// Otherwise use the current value
cur[ node ];
// If this leaf finishes the word
if ( node.length === word.length ) {
// Return 'true' only if we've reached a final leaf
return val === 0 || val.$ === 0;
// Otherwise continue traversing deeper
// down the tree until we find a match
} else {
return findTrieWord( word.slice( node.length ), val );
}
}
}
return false;
}
Note that we have to do the indexOf and slice operations on the word in order to get at the proper substrings that we need for comparison. Additionally we have to make sure that we substitute in the suffix objects that we’ve removed previously. In all it’s likely to add some level of performance overhead, compared with a traditional Trie, but considering how fast it is already that hit really ends up being negligible.
Further File Size Optimization
I did two final tweaks to save on file size. First, I remove all the quotes in the file. Yes, this makes it no longer valid JSON – but that’s OK for my particular situation (I’m loading it as a JavaScript file). Second, I go through and re-quote all the reserved words that are used as object property names. Thus { for: 0, in: 0, zoo: 0 } would become: { 'for': 0, 'in': 0, zoo: 0 }. This final result makes the best use of file size while still working properly in all browsers.
File Size Analysis
The biggest win provided by a Trie should be related to its decrease in file size. The plain string dictionary contained 112,429 words in it and clocked in at 916KB so it seems like any decrease should be possible.
I did multiple levels of comparison. Comparing the basic string version of the dictionary (that I discussed in the last blog post), the simple Trie (no optimizations), the optimized Trie, and the suffix optimized Trie.
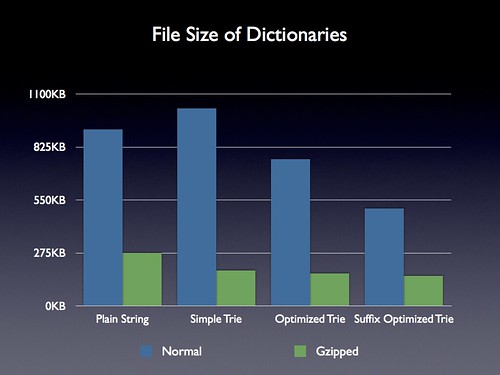
The result is quite interesting. The unoptimized, uncompressed, Trie is actually slightly larger than the plain dictionary – but shows some solid benefits once compressed. The further optimizations yield even better results. The final suffix optimized, gzipped, Trie yields a file size of 155KB compared to the initial 276KB of the plain string dictionary. Not bad for over 110,000 words!
Load Speed Analysis
If I was only interested in the download size of the dictionary I would’ve stopped there – however I want to make sure that no other aspect of the application will be hurt by making this switch. Specifically I want to make sure that loading in the dictionary (converting it from a serialized JS string into a usable form) was still fast. I want to make sure that when I do an Ajax request to get the dictionary, or when I load the dictionary from localStorage, the resulting overhead of parsing all the code doesn’t cripple the application.
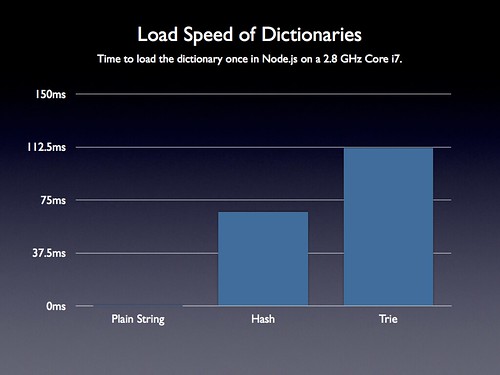
Unfortunately this is where we start to see some serious problems with using anything but a plain string. In the above chart I include the plain string dictionary and the Trie – but also the hash-lookup technique that I described in my last post.
Note that this load process is going to happen every time the application starts (for example having to re-parse the serialized Trie into a usable JavaScript object).
In the above chart I’m only analyzing the code in one of the fastest JavaScript environments in existence: an unhindered Node.js running on a Core i7 processor – and even then loading the Trie dictionary takes over 100ms. I fear how long it would take on a mobile phone or in an older Internet Explorer browser. If you’re wondering why this might be the case think about what’s happening here: You’re loading and evaluating over 506KBs (after being un-gzipped) of JavaScript code. This will bog down any system – especially a phone.
To drive the point home I ran some tests in some browsers:
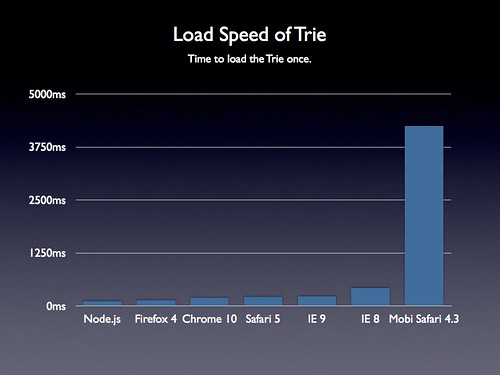
Sure enough – even one of the fastest mobile browsers (Mobile Safari 4.3) takes over 4 seconds to load the Trie data structure! In fact it crashed the browser on a few test runs.
Considering that Gmail delays nearly all execution of its JavaScript code, on mobile devices, requiring 506KBs of JavaScript code to be executed up front becomes untenable.
Search Speed Analysis
I didn’t want to stop there, though. There were (justified) concerns in reply to the previous post regarding the lookup technique being employed to find words in the plain string dictionary (it was using a simple indexOf operation). This is a linear search through the string and will undoubtedly be much slower than using a Hash or a Trie lookup.
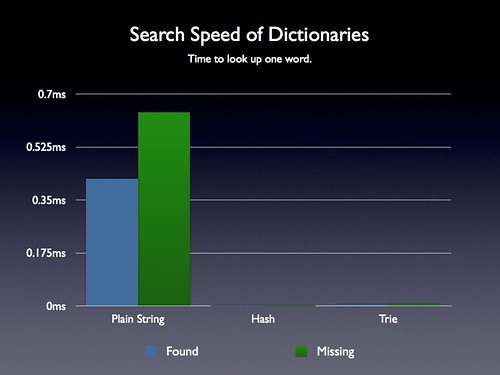
I ran some tests (for both finding valid words and invalid words) and confirmed that suspicion: Doing a linear search across a plain string is fundamentally much slower than using a hash or a Trie. However – note the time scale. In the absolute worst case searching the plain string dictionary for a word yielded lookup times of less than one millisecond. Considering that in my game dictionary lookups are only happening every couple seconds (and not thousands of times a second) I can get away with this performance hit. Presumably if you were building a game that required multitudes of dictionary lookups you might want to go with a faster hash or Trie technique.
Memory Usage Analysis
Finally I decided to take a look at memory usage. This was one last factor that I needed to take into account, with regards to mobile. Using too much memory will cause a web site to reload if the user switches tabs on an iOS device – and will likely cause similar problems on other mobile devices.
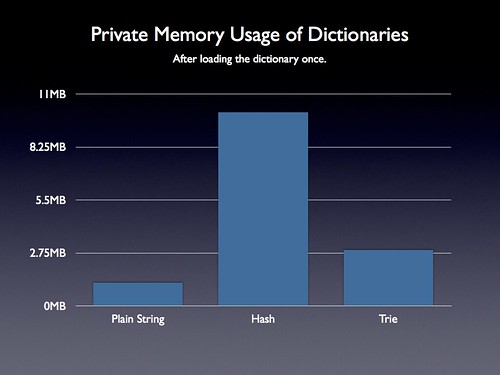
Once again, having a simple object yields some impressive gains. Using just a plain string (even though it’s 916KB) still ends up using less than half the amount of memory that a Trie structure does – and almost 10x less than a naïve hash.
Raw Memory Usage Data:
(I loaded the dictionary 100 times in Node.js in each case in order to try and get an accurate reading from OS X’s Activity Monitor monitor application.)
Baseline memory usage of an empty Node.js application:
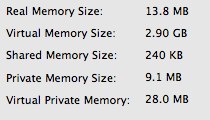
Memory usage of a the plain string technique:
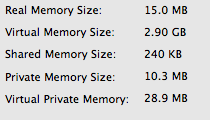
(Note that even though I loaded the dictionary 100 times it appears to have been smart and cut down on duplicate memory usage. I even tried to inject some randomness into the dictionary string but still ended up with similar results. I ended up just counting this result once, rather than dividing by 100 like with the other results.)
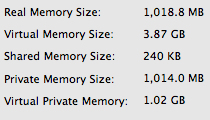
Memory usage of the hash technique:
Memory usage of using a Trie:

Conclusion
So while utilizing a Trie structure could yield some rather significant file size and word lookup performance improvements – it comes at a cost that is rather unacceptable for an application that’s attempting to target older browsers or mobile devices (both in terms of initial load and in terms of memory usage).
I hope the Trie JavaScript code that I’ve written can be useful to some either way.
If anything though, I hope to communicate that when you are making decisions about what technologies to use – just because something may sound better on paper you really should do some careful analysis of the solution before moving ahead.
Raw Data
The raw data for all my tests (which can be found in my Trie.js Github repo) is as follows:
Plain String -------------- Normal: 916KB Gzipped: 276KB Build Speed: 1 (.01 per) Find Speed: 47331 (0.42ms per) Not Find Speed: 71902 (0.64ms per) Private Memory: 10.3MB (1.2MB per) Hash -------------- Normal: 916KB Gzipped: 276KB Hash Build Speed: 6638 (66.4 per) Hash Find Speed: 19 (0.0002ms per) Hash Not Find Speed: 34 (0.0003ms per) Private Memory: 1014MB (10.05MB per) Trie -------------- Simple Trie: 1.0MB Gzipped: 184KB Optimized Trie: 761KB Gzipped: 168KB Suffix Optimized Trie: 506KB Gzipped 155KB Build Speed: 11178 (111.8 per) Find Speed: 413 (0.004 per) Not Find Speed: 552 (0.005 per) Private Memory: 299.2MB (2.9MB per)
Update: Early this morning Mike Koss posted a follow-up on my previous blog post with a compressed Trie implementation. This is quite interesting and will certainly result in a smaller file size than what I’ve done. However, there’s a problem: The result will end up taking a longer amount of time to load than the plain JavaScript structure that I employed. In my solution, since it’s already written using JavaScript syntax, the performance will run as fast as the JavaScript engine can parse the code. However in Mike’s solution the corresponding JavaScript structure will need to be re-built from the text itself. Theoretically if Mike comes up with a solution that used the compressed file size but leaves the data in its original string – that would be the best of all worlds. I’ll be curious to see what he comes up with!


Chris Moyer (March 17, 2011 at 10:00 am)
Very cool!
It’s so easy to get caught up in doing things _better_, that you lose sight of the benefits of simple. And this clearly underscores the value of benchmarking all facets of performance when you attempt optimizations.
gradbot (March 17, 2011 at 10:16 am)
Why not make a hybrid? Use string search and the trie structure. Once a node gets beyond a thousand characters split it. The trick would be figuring out the best way to split it fast.
John Resig (March 17, 2011 at 10:22 am)
@gradbot: That seems like a not-optimal combination. What you want is a string structure (optimal memory usage) and a trie search (fast lookups, optional file size)! (As I noted in the update at the end of my blog post).
Jeremy Martin (March 17, 2011 at 10:27 am)
Awesome article – very thorough on the numbers! Just thinking out load, but can arrays be parsed faster than object literals (since there’s no hashing on the properties required)? If so, it seems like load times could be reduced by sending down the trie(-ish) structure as nested arrays. E.g.,
// array version of above example
var trie = [
['bar', '$', 's'],
'foo',
['rat', '$', 'e']
];
There’s a minor benefit here too in that it serializes smaller, but that’s not the main point. The idea then would be that when it came time to actually search the trie(-ish) structure, the arrays would be lazily converted into objects, thus spreading the labor out over time, and hopefully avoiding a lot of it altogether. That all of course depends on whether or not it’s actually cheaper to parse arrays (which the less lazy version of me is out there somewhere making a test for…).
John Resig (March 17, 2011 at 10:31 am)
@Jeremy: I don’t think there are, particularly, any significant performance benefits from using Arrays instead of Objects. The part that “hurts” so much is simply parsing a 500KB+ JavaScript object. It doesn’t really matter what JavaScript code is inside there, it’s going to take a long time (relatively speaking) to load that blob.
Jeremy Bowers (March 17, 2011 at 10:41 am)
Use old C-ish flatten-complicated-structures-into-arrays trick and push down a Trie that is encoded in a simple string? All the parse speed of the string lookup, quite possibly better lookup performance too.
Peter Keane (March 17, 2011 at 10:45 am)
Am I right in thinking that if something like the (proposed) IndexedDB specification is completed and widely implemented in browsers this all becomes moot? I certainly see the benefit of client-side data crunching, but it seems to me we need native support in the browser (which you get by coming up w/ a good spec that gets implemented).
Thomas (March 17, 2011 at 10:45 am)
If two points make a line, why not just use tuples or graph “edges” or an EAV datamodel, or whatever you’d call it, a sparse matrix. I would think a straight large array of tuples would have less computational work, but I don’t study these things day in day out, so this may well be essentially the same thing? Perhaps I’m saying the same thing as Jeremy, I would expect the object to have more computations trying to keep track of the deepness of the relationships, whereas a list is a list. Granted, resolving a relationship may take rescanning the entire list.
John Resig (March 17, 2011 at 10:53 am)
@Peter: IndexedDB may help a bit in this case. It’ll cut down on memory usage (at the cost of additional reads on the disk – which will likely increase battery usage on mobile devices) and may decrease search time. Although easily the biggest benefit of my current technique is that it’s capable of easily using
localStorage– and that has fantastic cross-browsers support (in contrast with IndexedDB, which doesn’t).Lon Ingram (March 17, 2011 at 10:56 am)
Given the completely adequate lookup performance of the string search, it’s not really necessary, but I think it’s worth mentioning that a good compromise might be to build the trie asynchronously using setTimeout. A lookup would then be a two-step process, checking the trie first and then the string. Total memory use will be higher, of course.
Josiah C. (March 17, 2011 at 11:02 am)
Two comments.
First, you should really try keeping your wordlist sorted and using a binary search on top of it. You would move from on average 50k word scans down to around 8 when searching for a particular word.
Secondly, the use of an array for X items in the leaves as an array, but internal nodes as a trie is called a “burst trie”, and has a lot of convenient features: it is faster to construct (you split nodes on creation, not compress nodes after creation), reduces node splits to a minimum (reducing parse time and object construction time), and naturally compresses the data to a very reasonable middle-ground, depending on your choice of X. Typical “X” in literature where it is discussed uses X=256.
Sam Fo (March 17, 2011 at 11:12 am)
Kudos for posting a negative result John, many would have buried it as a failed experiment, but there’s lots to learn here and like you say it may end up being more useful elsewhere.
Adam Sanderson (March 17, 2011 at 11:49 am)
Thanks for posting this, it’s actually quite applicable for me right now since I’ve been making an browser based word game.
I tried a trie, but in the end, if you’re doing exact matches, just loading a javascript hash that the browser will cache is good enough. One minor way to trim down the size of the hash is to omit quotes on any keys that aren’t reserved word in Javascript.
I’m actually surprised that doing an indexOf is that fast, I assumed from the start that it would be too slow, but those results sound pretty good. A trivial modification you could make would be to split up the string by the first letter, which would partition it a bit, but should make almost no difference to load time.
John Resig (March 17, 2011 at 11:58 am)
@Adam: Be very careful when using a hash of all the values – as I noted in my results it uses the most memory of any technique and has a rather significant load time (not as much as the Trie, but up there).
skco (March 17, 2011 at 12:39 pm)
You can separate the structure into several files. Increasing the number of http-requests is usually against most common guidelines but once your parsing-time goes beyond a certain threshold you can actually gain performance by downloading part2.js while part1.js is being parsed. Especially if you do manual crunching on the contents of the file, not sure if pure js-parsing will be heavy enought to show improvements.
I don’t know if it’s as simple as just placing them as a list of script-tags but i know it’s possible to do manually with xmlhttp.
This of course only optimizes the full download+parse pipeline and might not be of use in your case where you want to use the cache. Maybe for the first use of the application though.
Michael Maraist (March 17, 2011 at 12:42 pm)
Obviously the build time would of a 100K node tree is expensive, so just use a pre-built binary representation.
If you KNEW you only cared about ‘a’ .. ‘z’, then you could use a semi-dense matrix x[26][] Where each node is the array offset of the next node. But to avoid javascript parsing, leverage the fact that this is read-only.. So you can make all indexes relative. Lets say the largest range is within 65K frames.. This means we can use 2 byte addressing.. Maaaybe squeeze it in 3 bytes.
Now we can cheat using 100 == “\100” and 0 == “” and 255 == “\255”.
We COULD have used hex, but that would have added hex encoding time.. Now we can just get 8 bits at a time and concatente them into a number that represents the next node ID.
We can compact the map slightly by offsetting the first element and last element. So if we have one node that has both an ‘a’ and ‘z’ symbol, we’re screwed. But if we have two chars ‘m’ and ‘n’, then that entire node only needs to consume 2 address slots. (by offseting the starting pointer by 15 symbols).
You’ll likely need to store state.. One way to handle collisions with such offseting (above) is to have one of the state-nodes the same as the starting address.. Thus we’d need two characters for each symbol to represent the next pointer and 2 chars to represent the current node-id.. Then probably another character to contain a bitmap of the rest (things like terminal node, v.s. valid node, but more nodes exist deeper, prefix-matching flags, etc).
The 2 byte addresses can work if you can successfully keep all relative links with 65K of each other. Alternatively each node can have a frame-header which defines how many bytes necessary to build that node.
That way leaf and near-leaf nodes can survive with just 1 byte addresses..
The server-side generator can do all this work to determine the most compact solution.
Tiago Serafim (March 17, 2011 at 12:44 pm)
I’m planning to make a browser-based word game too. Thinking about it, I’d try first on a client side BloomFilter and, on a match, an ajax query to see if the word really exist. Now I’ll try a simpler approach like a plain string. Thanks!
Kent Beck (March 17, 2011 at 1:19 pm)
I’m curious why you didn’t dynamically change the prototype slot of the leaf nodes to represent the different behavior required to process a leaf. I’m also curious what the performance implications of this sort of change are versus explicit if statements.
Sufian (March 17, 2011 at 1:21 pm)
Fantastic entry, I really like the analysis here.
But why set the baseline control as a linear search through the full dictionary string? Surely the full dictionary string itself has a separator between words, so it wouldn’t be terribly hard to implement a binary search (or even better in this particular case, interpolation search) on that string.
Half-baked idea: something makes me think that Huffman-encoding would be valuable here, but I haven’t thought it through completely…
Randall (March 17, 2011 at 1:31 pm)
The binary search from the other post (comment late last night, credit Mathias for the key idea) sort of seems to get the best of both worlds here. The dictionary is an array of 13 items (each a string or undef), loads via plain JavaScript parsing, is slightly smaller (not much) than the plain dictionary file on disk and should be the same in RAM. Lookups don’t scan the string. Doesn’t take tons of code, either.
(I messed up the last line of the dictionary-making command even in the “corrected” post. Replace that second single quote with “> dict.jsonp”.)
I confess, though, that even if it is an optimization, it’s a premature one. :) 100K words isn’t a lot for a computer to scan through nowadays!
I really like the deeper point here, that it’s missing the point to think only about lookup time. The urge to make things go fast is a basic trait of us coders, but sometimes we make the wrong things go fast. :) And data structures aren’t costless in JS — there’s real memory overhead for each string or object — and builtins are often very well tuned.
Jeffrey Gilbert (March 17, 2011 at 2:12 pm)
John,
With the trie file, does the file contain any whitespace? If so, shouldn’t that be removed prior to sending it? zip and compression aside, that seems like the thing to do to get the file size way down. Seems like if there were more of a filesize bonus for trie, it might offset the load time a bit.
Mike Purvis (March 17, 2011 at 2:15 pm)
I like the idea of chunking up the final blob and pulling it down in pieces. At the very least, then you’re able to show the user a progress indicator while the game “loads”, not to mention parallelizing the parsing and downloading.
An alternative to breaking up the list by word length would be to just pack them all in one list alphabetically, and then do the binary search based on nearest-next, where you grab a substr of length 2*max and extract the word from that substr. This only really works if your dict has a fairly short maximum word length, but for many word games, that’s the case: the longest words you need are 8 or 10 chars.
This seems like it has the potential to be faster in the load stage, because you never actually “parse” the file, it really is just text/plain which is always treated as text and dumped into a single gargantuan string var.
John Resig (March 17, 2011 at 2:29 pm)
@Jeffery: Nope – no whitespace!
@Sufian, Randall, Mike: I fully expect to explore optimizations for searching through the file very soon. Although, as I mentioned before, given its current performance the priority for doing so was quite low. Thanks for the suggestions!
Valentin (March 17, 2011 at 2:38 pm)
Like Tiago Serafim the first thing which came to mind was a Bloomfilter. Did anyone try this? You could combine Bloomfilter with AJAX or with a hashtable.
Steve Krulewitz (March 17, 2011 at 3:14 pm)
John — I did something very similar to this for my Greasefire Firefox extension (https://addons.mozilla.org/en-US/firefox/addon/greasefire). In my case I was searching a database of hundred thousand URLs rather than words. For my trie implementation, I did a binary serialization of the tree rather than a JS data structure. This way it is as quick to load as the “plan string” and pretty fast to search, although I never benchmarked it :)
Jacob Rus (March 17, 2011 at 3:25 pm)
Hi John,
I bet you’d get substantially faster performance than the straight string lookup if you used a regexp instead. I’m not sure how fast regexp compiling is once they get that big, so it might be best to e.g. make a couple of levels of trie first for the first couple letters, and then only compile and cache a regexp at the next level once it’s called upon (you could obviously do the same for your existing trie/dictionary lookups to cut down load time). Anyway, your regexp can basically be the same structure as your “optimized trie” (not the “suffix-optimized” version), and I would expect the regexp matcher to traverse it rather faster than a hierarchy of javascript objects can be traversed.
Cheers,
Jacob
Mike Koss (March 17, 2011 at 3:45 pm)
Hi John,
Glad to hear you’re interest in my Trie solution. I just implemented the PackedTrie class – that uses the compression representation of the Trie string. So you can download that, and not have to reconstitute any JavaScript objects; PackedTrie.isWord() uses the compressed string representation directly (actually, after split-ing it into an array of strings).
You can test it out here:
http://lookups-dev.pageforest.com/
And the source code is on GIT (MIT License – so anyone is welcome to use it):
https://github.com/mckoss/lookups
Next up – I’ll try implementing a suffix-sharing encoding. I have a nice idea for that. Note that references to other nodes are now the differential node number. I plan to utilize UPPER CASE strings, as references to “named nodes”. So, all those places in the Trie that indicate an optional plural string (“!s”) can now be reference with a single character. E.g., suppose we have dictionary:
cat cats
car cars
cards
cop cops
The compacted Trie is:
c1
a1op4
t1r2
!s
!s,ds
!s
In the new version this becomes:
S:!s
c1
a1opS
tSr1
!s,ds
The first line defines a named node (S), that can then be used anywhere a node reference is allowed.
The lookup will be just as fast as before, but the collapsing of suffixes should save quite a bit of storage over the simple Trie…
thetoolman (March 17, 2011 at 4:05 pm)
Hey, just thought I’d mention that I implemented a trie structure for my JQuery plugin: UFD. My implementation is pretty basic, so maybe I can leverage your work :)
http://code.google.com/p/ufd/
thetoolman (March 17, 2011 at 4:07 pm)
Here is my post on infix searchin using a trie:
http://blog.toolman.geek.nz/2010/03/infix-search-using-trie-data-structure.html
Stephen Jones (March 17, 2011 at 4:12 pm)
@Mike Koss: You might consider the suffix bitmap encoding I outline in a comment on the original post:
http://ejohn.org/blog/dictionary-lookups-in-javascript/#comment-392092
It compresses sets of words like this:
flex, flexed. flexer, flexes, flexing, flexible, flexibly, flexibility
down to this:
flex:FF
where FF is a bitmap of 8 possible suffixes for flex.
Mike Koss (March 17, 2011 at 4:35 pm)
@Stephen Jones: I think that’s pretty similar with what will fall out of the general case. Rather than choose a fixed set of suffixes, the common-suffix elimination step would determine the common shared suffixes from entries in the dictionary. I would then encode these as one more more upper case letters to represent the shared pattern.
Fabio Buffoni (March 17, 2011 at 6:29 pm)
Here’s another approach you can try.
Transform you giant string using bwt (burrows-wheeler transform).
Apply a simple compression on the output, run-length-encoding should be be simple enough and gives good results.
Keep your string in a compressed form and perform searches directly on the transformed stream (a binary search should be very very fast).
Implementation would be quite tricky, but I think it can give smaller transfers and very good performance.
kowsik (March 17, 2011 at 6:45 pm)
I started working on a memcouchd project a while back (not complete yet) where I implemented a (partial) BTree with nodejs. I was seeing a million inserts over 3 seconds with full rebalancing on my Mac Book Pro. Might want to check it out: https://github.com/pcapr/memcouchd
Mike Purvis (March 17, 2011 at 7:49 pm)
I suspect that the solution Mike Koss has posted will be the best so far in terms of both performance and wire size—I had much the same idea on the way home from work, but he’s already totally nailed it.
Wes (March 17, 2011 at 9:02 pm)
It seems that a simple optimisation to the plain-string implementation would be to sort the words within the string and then create a small index that mapped each letter of the alphabet to the index in the string in which it first ocurrs. The index could then be passed to indexOf to start the search from the first letter, skipping all the words that won’t match. This might work even better if the words were sorted z-a since its possible that words beginning with the first half of the alphabet are more prevalent (I haven’t checked this).
David Stafford (March 17, 2011 at 10:11 pm)
Here’s an example of decoding and searching a DAWG in real-time in javascript.
It encodes a dictionary of 106,495 words (an old Scrabble dictionary) into 427,982 base64 characters.
http://www.davidst.com/jsanagram/
Note: This was an experiment to see if javascript could be fast enough to do this sort of thing. It was never finished. The count of anagrams should be updated and the crossword finder should be hooked up. Feel free to take it and hack on it if you like.
Jacob Swartwood (March 18, 2011 at 1:00 am)
John, have you looked into saving indexes for each letter at the start of their words
var starts = { ... s: dict.indexOf(" s"), ... };and running substr before searching a word? Or likely better yet, a simple map/array of just a few substr results split at the most common letter prefixes. You could do this once after the data is loaded without giving up too much of the string benefits, yet improve speed on subsequent indexOf calls. Would that have enough additional speed improvement to warrant the compromise of some additional memory usage?Abrahm Coffman (March 18, 2011 at 2:01 am)
Couldn’t using webworkers and map reduce provide better search/filter/sort performance?
Ryanne Dolan (March 18, 2011 at 11:15 am)
John,
Your implementation uses JSON/JavaScript objects which are themselves HASH TABLES. Instead of replacing your hash table method with a faster trie method, you naively are using a HASH TABLE to store a trie. That kinda defeats the purpose right? In fact, each time you look up a node in the trie, you are performing the same HASH lookup you performed in your first implementation.
Instead, you should implement your trie data structure and algorithms using only arrays and array lookups. This would get you the speed boost and memory reduction that everyone is promising. In fact, this is the WHOLE POINT OF TRIES in the first place.
(cross-posted from Google Buzz discussion)
Beecher Greenman (March 18, 2011 at 12:26 pm)
@Ryanne Dolan: That would help in languages where arrays and hash tables weren’t one and the same, like C or Java or Python. But you can’t escape the hash table in JavaScript: Arrays are objects, so they’re hash tables too (though with a little magic coded into the length property).
Ryanne Dolan (March 18, 2011 at 12:34 pm)
@Beecher Greenman,
That’s not necessarily true:
http://news.qooxdoo.org/javascript-array-performance-oddities-characteristics
It’s plain false in modern browsers.
Mike de Boer (March 19, 2011 at 7:26 am)
Hi John Resig,
I very much enjoyed the write-up of your experience while diving into algorithms and specifically the trie data structure. I am quite sorry that you didn’t search for a Trie implementation in JS on Github, because you would’ve found my implementation here:
https://github.com/mikedeboer/trie
and more specifically the implementation here:
https://github.com/mikedeboer/trie/blob/master/trie.js
… which consists mostly of comments. I created it mainly during my own study on the subject but quickly learned that the implementation works extremely well, so we started using it in various places in production (for example, cloud9ide.com and the Cloud9 IDE).
Be aware that it is not a generator/ parser for a trie structure, but an in-situ trie data structure that is resident in memory. I hope you find the time to try it out and see the little benchmark/ test I also included in the repository.
I’m not at all looking for acknowledgement for my work (been there, done that ;-) ), but mainly to share knowledge and hope to contribute something useful to the public and JS community in the process!
Enjoy and have fun!
Regards,
Mike de Boer.
Christian Harms (March 20, 2011 at 4:05 am)
At this time all hasmap/trie data structures ends with a huge memory usage on the JavaScript side! I made detailed comparison between the filesize and String, Hashmap and Trie variants.
http://united-coders.com/christian-harms/create-optimized-wordlist-data-structures-for-mobile-webapps#conclusion
An fixed-length String with binary search is a moderate solution.
Henning Peters (March 20, 2011 at 6:16 pm)
Hi John, thanks for sharing your benchmark results, quite interesting.
Please consider one more data structure that – as far as I can see – wasn’t discussed before, sorry for joining a little late into the debate:
Compressed suffix array (http://en.wikipedia.org/wiki/Compressed_suffix_array)
Think of them as a bzip2 archive on which you can perform fast string search (without uncompressing it, of course).
Unlike tries/suffix trees they achieve fast lookup while also having sub-linear space requirements in terms of text size for most practical cases. For construction in memory you will never beat the string copy – unless you work with external data structures and fine-grained disk access which I guess the HTML5 storage API does not support.
Implementation complexity for compressed suffix arrays might be quite high, but you would most certainly save significant amount of memory compared to plain text. Drawback is that you lose locality of access, so it does not perform well on external memory – which is not feasible anyway.
John Resig (March 20, 2011 at 9:51 pm)
@Jacob Swartwood: I actually had that same idea just the other day – definitely going to give it a try.
@Ryanne Dolan: You’re again missing the point – my concern isn’t with the lookup speed, there could definitely be performance improvements there (many of which have been listed here). My concern is with the physical construction of the array at load time. Constructing an object that holds approximately 500KB of data will take significantly longer than just using a plain string – and considering how slow mobile devices are I don’t think it’s an unjustified concern.
@Mike: I did see your implementation – but I discarded it as there was no way to generate or parse the data structure (which was almost entirely what I was interested in). Unfortunately I couldn’t feed my data structure into your implementation as I used different compression techniques that yours didn’t support. Either way, keep up the good work!
Randall (March 21, 2011 at 3:08 pm)
@John — I probably sound like a broken record or something, but I just want to add, empirically, binary search + Mathias Nater’s idea for how to format the dictionary improves lookup time and does no harm to file size, load time, or RAM use, at least in Chrome 11 on my netbook. :)
Again, the trick there is to create an array of a few strings, each of which has all the words of length n run together without delimiters. Then you can skip back and forth through one of the strings using the substr method much as if it were an Array (and do binary search), with just the RAM/construction-time cost of a few regular strings. Credit Mathias Nater for the idea to store the dict that way.
To get specific on different aspects of performance, dictionary size is 544KB for Mathias’s dict format vs. 625KB for a space-delimited dict (I’m using another Scrabble dictionary; couldn’t find yours). 227KB vs. 239KB gzipped. Re: parsing time, the “Evaluate script” timing I got for loading Mathias’s dict format in Chrome’s inspector’s Timelines tab, averaged acorss three runs, was ~59ms vs. ~75ms for a space-delimited dict — I’d guess that’s either random noise or because of the file-size difference. RAM usage is similar: 1.50MB in Chrome’s heap profile for the binary-searchable format, 1.58MB for the space-delimited dict. The time I measured for a failed lookup was .001ms. Obviously you could do more investigation — I can’t conveniently test on IE 8, e.g. — but I hope it’s enough to show the idea isn’t silly on its face.
(The point is not to congratulate myself on those stats — there’s nothing that novel or valuable there. And I’m squarely in the pragmatic camp that thinks 0.7ms to check a word (or a few ms on a smartphone) is just fine; 50ms’d be fine. Likewise, if there’s some reason this won’t really help (e.g., if substr’s pathologically slow on long strings on IE 8, just hypothetically), fine.
Just, this *is* a thread about performance analysis, so want to register why I think this approach might be promising. :) )
Here’s the code with the corrected dictionary maker:
sort dict.txt | perl -e '
while(<>) {
chomp;
$a[length $_] .= $_;
}
print "loadDict([\n";
print qq| "$_",\n| for @a;
print qq| ""\n])|;
' > dict.jsonp
<script>
var dict;
function loadDict(d) { dict=d; }
function exists(word) {
var l = word.length;
if ( !dict[l] ) return false;
var words = dict[l].length/l;
var low = 0, high = words-1, mid = Math.floor(words/2);
while (high>=low) {
var found = dict[l].substr(l*mid, l);
if ( word == found )
return true;
if ( word < found )
high = mid-1;
else
low = mid+1;
mid = Math.floor((low+high)/2);
};
return false;
}
</script>
<script src="dict.jsonp"></script>
John Resig (March 21, 2011 at 5:10 pm)
@Randall: That’s some very cool stuff – thank you! (And thanks to Mathias as well!) I’ll see if I can do some additional testing and do a write-up on your technique.
Mohamed Mansour (March 21, 2011 at 6:22 pm)
Hi John, take a look at Steve Hanov solution using Succinct Data Structures.
http://stevehanov.ca/blog/index.php?id=120
Pretty cool :)
David Karger (March 22, 2011 at 2:00 am)
By compressing single-letter nodes, you’re halfway towards reinventing the suffix-tree data structure (mentioned a few comments previously). Suffix trees also have an advantage that if you _know_ the string you are looking for is in the tree, you can find it faster by skipping over compressed nodes. However, practitioners generally avoid suffix trees in favor of suffix arrays, which offer pretty much the same performance (and likely better memory access patterns because they use an array instead of a tree) while using less space.
David Karger (March 22, 2011 at 4:41 pm)
Also, if you’re stringing together all the words in your dictionary, a suffix array (which is basically the same thing) will also let you search for substrings in your dictionary.
Mike Koss (March 22, 2011 at 6:53 pm)
Hi John,
I finally finished up my compressed Trie solution. You can play with the code here:
http://lookups.pageforest.com
Using this Trie format, the ospd3 dictionary compresses from an original 625K down to 180K (114K gzipped). Note that the JavaScript PackedTrie (itself under 800 bytes minified and gzipped) can accept this string as is, and do searches against the data (it does a one time split on the string to break it up into an array of strings).
This implementation is actually a DAWG (directed acyclic word graph) – all the nodes that share the same suffix point to the same node in the Trie.
On an earlier attempt, the file was overly large because of large relative references between nodes (represented by numeric strings of the difference between node numbers). I first converted all node references to “base 36.1” encoding. Now all node references fit in 3 characters. Next, I implemented a node reference aliasing. When it will reduce the file size, I replace the relative reference to a node with a single-character (absolute reference) as entered in a symbol table at the beginning of the file.
As a sample, here is the PackedTrie encoding for the words in the previous paragraph:
aPbLcIdifferenHeFfiEiClarge,n9o8re6s3t2w0
as,hMi0
ll,th
ab2he,o
i0trings,ymbol
ng0ze
le
duAferenceDlative,p0
la9res5
f,n,verly
ext,o1um0
bers,eric
de8w
!mplem0n,t
ent5
le,rst,t
arlier,n0
codBter2
ce
haracter1onvert0
ed
!s
a2e0y
cau1ginn5twe0
en
se
!bsolute,l1n,s,t0
!tempt
ias0l
ing
Note that there are no symbol definitions because all the node references are already single-character.
There are perhaps a few more tricks to be squeezed out, but I think I’m hitting the point of diminishing returns.
Ryanne Dolan (March 22, 2011 at 7:16 pm)
@Mike Koss,
Very clever. Love it.
Mike Koss (March 22, 2011 at 7:45 pm)
Thanks, Ryanne!
I just posted more complete documentation on the format in the GitHub READ.me:
https://github.com/mckoss/lookups
@John: feel free to use this code if you want. The data format can be generated with JavaScript (or even using the online hosted version I posted), and then a small (separate) run-time JavaScript can act as the decoder.
John Resig (March 22, 2011 at 11:30 pm)
@Mike: This looks awesome! I definitely plan on digging in ASAP. If it’s as small as you say it is then it’s definitely worth a shot.
Maxim (March 31, 2011 at 8:20 am)
Nice piece of information. The power of javascript is not known to all… Good job