A brand-new implementation of the Selectors API has landed in the latest Firefox nightlies (and in Firefox 3.1a1) – on track to head your way in the upcoming Firefox 3.1 release.
I’ve talked about this API before (1, 2) and while I do have some misgivings about the current API (which will be remedied in upcoming revisions of the spec) there is one thing that is undeniable about it: It is extraordinarily fast.
Thankfully, implementations haven’t scarified specification compatibility for performance and we can see both the Firefox and WebKit implementations coming in at 99.3% passing the Selectors API test suite. Opera is working on their implementations, slated for Opera 10, and Microsoft has an implementation in beta 1 of Internet Explorer 8. This means that by late this year all browsers will have an implementation of the Selectors API in the market.
JavaScript libraries have already been working to utilize this new API, preparing for when it’ll eventually be ready for all to use. The current score is:
- Dojo has querySelectorAll support in Dojo 1.1.1, although support for Safari 3.1 is disabled (there were troublesome crashing bugs in early versions of Safari 3.1 that have since been resolved).
- Prototype has querySelectorAll support in their Git repository (presumably to be rolled into their next release).
- jQuery has querySelectorAll support in an experimental plugin (to land in the next release).
This has lead to some interesting numbers (utilizing the same testing techniques employed by the WebKit team):
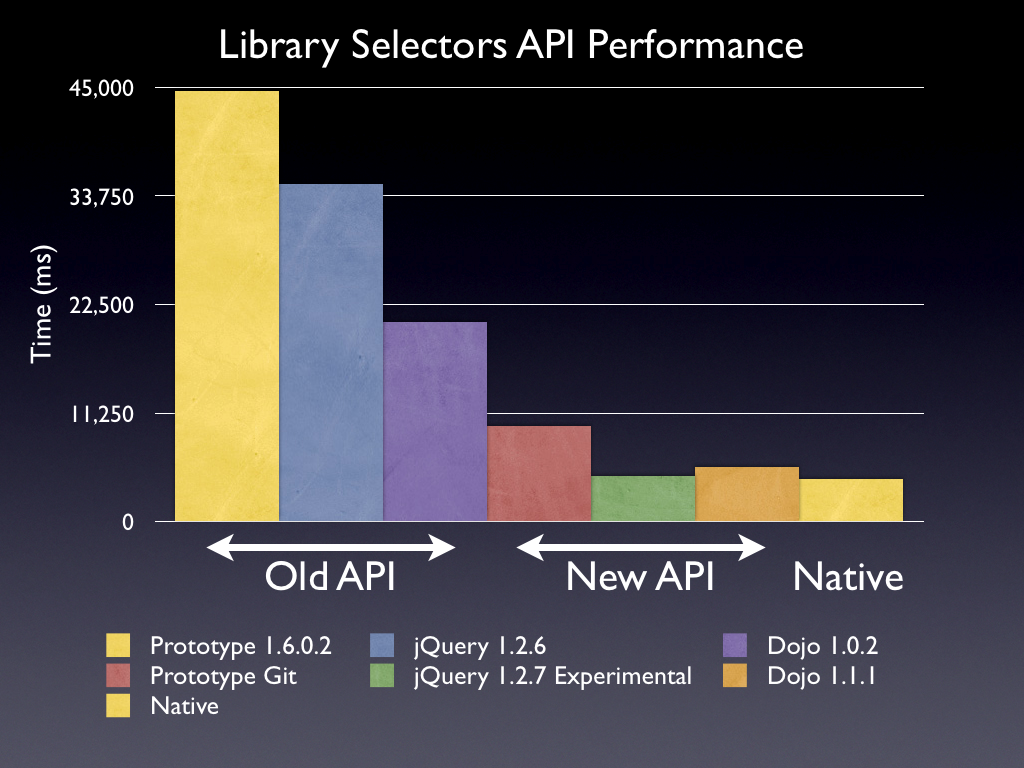
| Library | Time (ms) |
|---|---|
| Prototype 1.6.0.2 | 44677 |
| Prototype Git | 9914 (123% slower than native, 351% faster than DOM) |
| jQuery 1.2.6 | 35045 |
| jQuery 1.2.7 Plugin | 4731 (7% slower than native, 641% faster than DOM) |
| Dojo 1.0.2 | 20782 |
| Dojo 1.1.1 | 5669 (28% slower than native, 267% faster than DOM) |
| Native | 4441 |
That means that libraries that utilize querySelectorAll will be running 2-6x faster than their previous versions. This is already quite impressive.
There are two points to consider when using this API:
- That you need to try and keep the overhead on top of the querySelectorAll method as low as possible.
- That it becomes advantageous to avoid the querySelectorAll API in some extreme cases (for example, jQuery avoids it for #id queries, allowing it to go over 10x faster than querySelectorAll).
A lot of bare-bones selectors library implementations are going to look something like this:
function querySelectorAll(selector){
try {
return Array.prototype.slice.call(
document.querySelectorAll( selector ) );
} catch(e){}
return myOtherLibrary( selector );
}
Note two points: There’s a try-catch block there to capture any syntax errors that are generated by querySelectorAll (syntax errors could be generated by APIs that the implementation doesn’t understand – like jQuery’s div:first, for example). If no exception is thrown while retrieving the results we need to convert it into an array (most libraries convert result sets into arrays – or bless them in some manner).
Tackling both of these points will introduce some level of overhead in a library (on top of the native querySelectorAll implementation). Of course it’s never as simple as it should be, many libraries extend these return sets with additional functionality so the overhead will be that much greater.
Regardless it’s readily apparent that this API will be quite instrumental in trivializing one of the most difficult parts of implementing a new JavaScript library. Everything after this is just gravy.


Arnabc (August 21, 2008 at 12:01 am)
Pretty impressive, as per permormance, I hope, as you said, by the end of this year we’ll have this API implemented in all browsers.
Pelle (August 21, 2008 at 2:19 am)
Exciting news! I just have to mention that another library supporting querySelectorAll, even though not as big as the ones you’re mentioning, is DOMAssistant and I really have to agree that the performance gains from it are really big.
The gains are so big that it might even be an issue (?) that the performance in newer browsers are getting so much faster than in the older ones that javascript intensive applications might not work on IE 6 and similar.
Peter Bowyer (August 21, 2008 at 2:23 am)
And what do the numbers mean up the vertical axis on the graph? Until I read the text beneath (which a good data chart should save me from doing) I thought you were saying the new API was *slow*, because there were less iterations per second!
Come on, there’s no excuse for not labelling axes :)
John Resig (August 21, 2008 at 7:16 am)
@Arnabc: Time will tell – but I’m optimistic. WebKit is already out, IE has said they’ll be out by the end of the year, Firefox 3.1 will be out this fall – the only question mark is Opera 10.
@Pelle: I agree about the performance issues you point out. I think we’ll start to see more people inadvertently developing for these super-fast browsers, completely forgetting about the (still quite large) older percentages of the market place. Once again the ball-and-chain of web development slows us all down.
@Peter Bowyer: My mistake, I thought it was pretty obvious. I just uploaded a new version.
Peter Bowyer (August 21, 2008 at 8:49 am)
Thanks John, now no other mug has a chance of getting as confused as me!
Joeri (August 21, 2008 at 10:06 am)
That the new browsers are much faster could be a benefit in as much as it might be a soft encouragement to upgrade.
Brian McCune (August 21, 2008 at 12:03 pm)
Do you think that with IE8 coming out that we will need to continue supporting IE6. At what point must we force our viewers to upgrade?
Nosredna (August 21, 2008 at 12:10 pm)
>>jQuery avoids it for #id queries
Well shucks, the great majority of my queries are #id queries.
Jeff Uurtamo (August 21, 2008 at 12:15 pm)
@Brian
Sadly, I think we will be supporting IE6 for sometime. There are quite a few Multinational Corporations that still have set IE6 as the standard with no change planned in the future.
Kevin (August 21, 2008 at 12:54 pm)
I’m interested in how developers are dealing with their custom extensions to CSS selectors. In other words for “a:eq(2)” you could just run querySelectorAll on the first part, then filter the custom part. But then on “a:eq(2) div” maybe you just fall back to a custom implementation?
In general it seems like as long as querySelectorAll returned a superset of the results that the custom query would, it might still be usable?
Adam (August 21, 2008 at 1:33 pm)
“this API will be quite instrumental in trivializing one of the most difficult parts of implementing a new JavaScript library. Everything after this is just gravy.”
If you use Components then you don’t need selectors at all:
http://code.google.com/p/components-js/
I find apps using jQuery get scary pretty quickly. If you use Components you can access your page (and do everything else) through the object-mapping, instead of a ton of queries and method chains.
Jethro Larson (August 21, 2008 at 1:54 pm)
I think it’s good that we optimize for the newest browser techniques. Seems one of the big complaints about newer browsers is the responsiveness and bloat. If we can really utilize the performance increases it’ll help the newer browsers win that battle.
William J. Edney (August 21, 2008 at 10:51 pm)
As the submitter of the Bugzilla bug that got this rolling for Firefox, I’d like to give a personal thanks to Boris Zbarsky, who actually did the work!
Thanks Boris!
Cheers,
– Bill
Matt Krueger (August 22, 2008 at 8:57 am)
I’ve have a question about this. I hope someone answer. Why does it seem that there are soo many proposed approaches around to implementing selectors, when we already have xpath? Am I missing something?
Andrew Dupont (August 22, 2008 at 11:39 am)
@Matt Krueger: XPath is nice, and I still want to see it implemented in all browsers, but it’s also a complex domain-specific language with an awkward interface (I can never remember the order of arguments for document.evaluate) and pulls from a field of knowledge not directly related to client-side web development.
Querying by CSS selector involves a simple syntax that many people already know — and since all browsers need to know how to parse CSS selectors anyway, it’s easier to implement. And it’s far faster, too: in the above bar chart, Prototype 1.6.0.2 and Dojo 1.0.2 both use an XPath approach (already pretty fast), but the querySelectorAll approach is faster by almost an order of magnitude.
Mariusz Nowak (August 22, 2008 at 12:17 pm)
@John: A while ago you’ve had a post alarming that Selectors API spec is not compliant to what is convention in JavaScript libraries.
Has it changed? If not then above method of passing query to native Selector API (when available) may give different results on different browsers (?)
website designs (August 22, 2008 at 1:03 pm)
This is great! I hope it will put to rest all the “my selectors are faster than your selectors” contests that the frameworks have had over the past few years. With querySelectorAll everybody should be fast enough that it doesn’t matter anymore.
David Smith (August 23, 2008 at 4:39 am)
You may want to retest #id selectors in recent webkits, btw. I added (and Sam Weinig fixed my mistakes…) an optimization to use getElementById instead for those queries.
Anton (October 9, 2008 at 6:13 pm)
Hello,
please, what is faster / preferable way to select just one image with a path:
document.querySelector(‘image[src=”path”]’)
or:
document.querySelector(‘[src=”path”]’)
In other words, does it help that I know in advance that the only possible elements with that kind of attribute are going to be images?
Henrik Lindqvist (January 31, 2009 at 8:20 pm)
I’we put up a Slickspeed with many of the current implementations.
Prototype, jQuery and Dojo have some of the slower implementations howdays. Our Selector.js is quite fast and support almost all CCS3 selectors.