There’s a JavaScript feature that I feel needs much more attention: Native JSON support in browsers.
It’s something that should be a JavaScript language feature and yet no browser, or standards body, has defined, specified, or implemented what exactly it is, or should be. On top of this, it is one of the most (implicitly) requested language additions.
A recent ticket was opened for the Gecko engine, requesting a form of native JavaScript (de-)serialization whose API is based upon an implementation by Douglas Crockford. In effect, you’d be getting two additions to the JavaScript language: A .toJSONString() method on all objects (which will serialize that object to a string representation of itself) and a .parseJSON() method on all strings (which is responsible for deserializing a string representation of a JSON object).
I’d like to try and make the case for why I feel that native JSON support should standardized and made part of the JavaScript language.
1) The recommended implementation is considered harmful.
There are, currently, two popular means of transferring and deserializing JSON data. Each has their own advantages, and disadvantages. The two methods are:
- An implementation of JSON deserialization, by Douglas Crockford (which uses a JSON string, transferred using an XMLHttpRequest).
- And JSONP, which adds JavaScript markup around simple JSON data and is transferred (and deserialized) by injecting a <script> element into a document.
Currently, Crockford’s json.js is the recommend means of deserializing JSON data. This has been discussed extensively elsewhere. Currently, json.js is better at keeping malicious code from being executed on the client (JSONP has no such protection), and thus, is recommend for most use cases.
However, json.js has taken two serious blows lately, which has moved it from being “recommend” to “harmful”:
It’s possible to covertly extract data from json.js-deserialized JSON data.
Joe Walker recently exposed a vulnerability which allows malicious users to covertly extract information from JSON strings that are deserialized using JavaScript’s eval() statement. json.js currently makes use of eval(), making it vulnerable to this particular attack. This vulnerability has been discussed elsewhere too.
In order to fix this, json.js would need to use an alternative means of parsing and serializing the JSON-formatted string – a means that would considerably slower than the extremely-fast eval() statement.
It breaks the browser’s native for..in method of iterating over object properties.
At this point, its pretty safe to say that that extending Object.prototype is considered harmful – and many users agree. Extending an Object’s prototype is generally considered reasonable for personal situations, but for a publicly available, and highly recommended, script like json.js, it demands that it behave in a user-conscious manner.
Some attempts were recently made at cleaning up how json.js behaved, but thus far, no considerable effort has been made to provide an alternative means of deserializing JSON strings, that doesn’t break a JavaScript engine’s native behavior.
Summary: By adding support for JSON within a browser both of these issues will be completely circumvented (malicious users won’t be able to extract data from a JSON structure, nor will the parseJSON and toJSONString methods be able to break for..in loops).
2) The recommend method of deserialization doesn’t scale.
Let’s start by looking at the two most popular methods of transferring JSON data (JSONP and an XMLHttpRequest transferring plain JSON), along with using an XMLHttpRequest to transfer some XML data (just for fun).
I’ve set up a series of tests that we can use to analyze the speed and efficiency of traditional JSON (using json.js), JSONP, and XML. I made 3 sets of files each containing a set of data records. As a base, I used some XML data from W3Schools. In the end, I came up with a total of 24 test files, each with a different number of records, in each specified format.
- JSON: 25, 50, 100, 200, 400, 800, 1600
- JSONP: 25, 50, 100, 200, 400, 800, 1600
- XML: 25, 50, 100, 200, 400, 800, 1600
All of these get referenced from my mini test suites (one for each data type): JSON, JSONP, XML
These suites default to requesting the 50-record file 100 times, and taking an average reading. To get a reading on a different recordset, visit the file with the number of records in the URL, e.g.: json.html?400. Please don’t run this on my server, it’ll make it cry.
Instead, all of the test data and files can be downloaded here.
Note: I’ve only run these tests in Firefox, so caveat emptor.
Data Records by Time (in seconds)
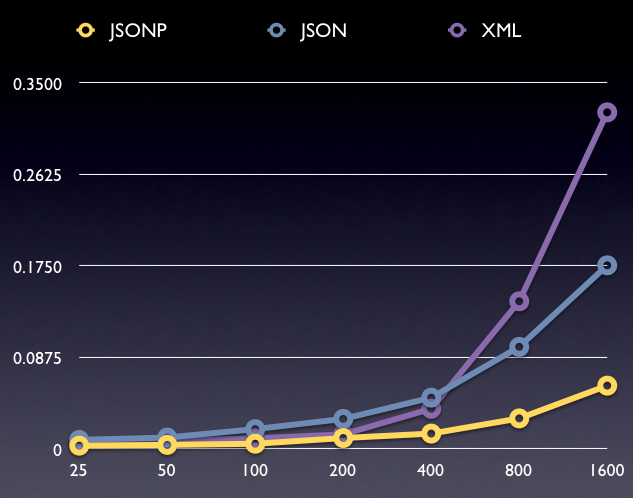
Right off the bat, we can see two things:
- Transferring and de-serializing JSON data scales better than doing the same for equivalent XML data.
- JSONP scales better than the (more secure) XHR-requested, json.js-deserialized, JSON method.
Looking at the numbers for the recommended means of transferring JSON data, we don’t get a full picture. Where are the scalability issues coming from? Maybe XMLHttpRequests don’t scale so well? (Which would also help to explain the numbers for the XML transfers.)
To resolve this, let’s break down the numbers for JSON into time spent processing and time spent transferring the data.
Data Records by Time (in seconds)
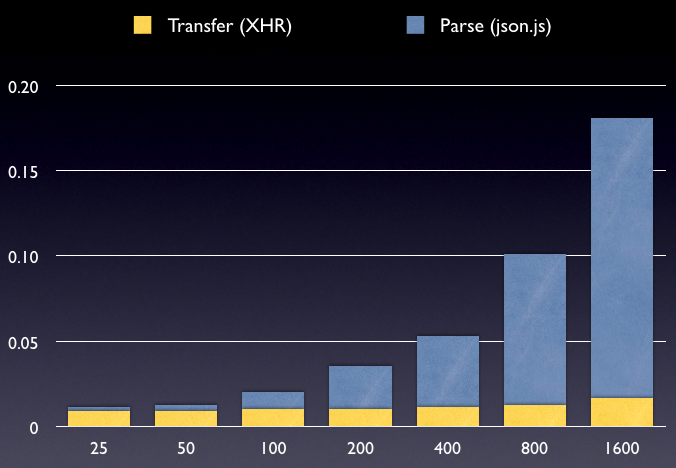
Here is where we see the major numbers come out. We can see that the processing time increases at a pace slightly less than O(n) time. This might be fine for most cases, however we can clearly see (from the previous chart) that JSONP is fully capable of faster parsing times.
Additionally, the processing time that json.js takes is completely blocking – no other operation is able to take place when the deserialization is taking place. When running the test suites you’ll find that when the high (200-1600) record sets are processed your browser will stall (and if you’re on a mac, you’ll get the spinner of death). By passing this complete operation off to the browser you’ll avoid all of these complications.
Summary By adding native JSON support within a browser you would have the blazing speed and scalability of JSONP, without adding any significant overhead.
In addition to studying the scalability of transferring JSON data, I’ve also looked at the overhead costs of pushing JSON data into an HTML structure (especially when compared to XML-formatted data).
Currently, some browsers have a native means of processing and converting XML data structures on the fly, using XSLT. XSLT is an incredibly powerful templating language and is more than capable of transforming any XML structure into an appropriate XHTML data structure.
However, for JSON data, no killer-templating system exists. I’ve used JSONT extensively but, in reality, it doesn’t hold a candle to XSLT. (Both in terms of features and speed.)
I have two test suites one for JSONP + JSONT and another for XML + XSLT. You can download the full suite here.
Data Records by Time (in seconds)
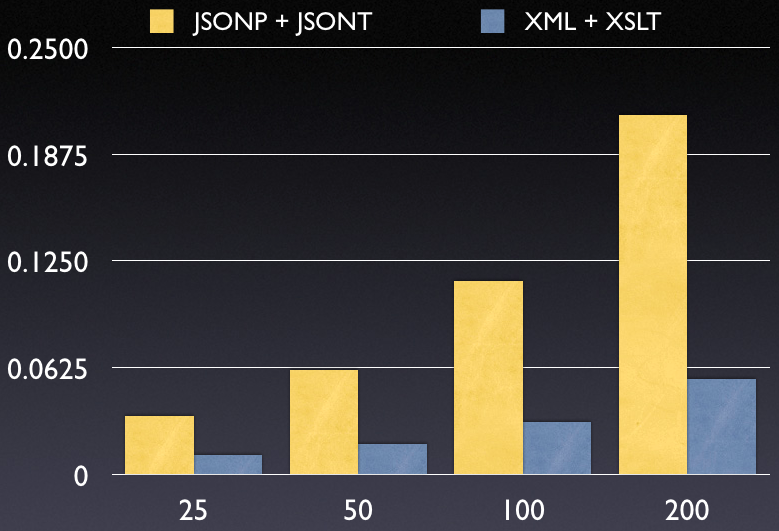
You can see that, even with the extra speed advantages of JSONP, all of that lead is blown away by the incredibly slow nature of JSONT. Unfortunately, the situation isn’t as clear-cut here as it was comparing JSONP and json.js, considering that JSONT is hardly a worthy replacement to XSLT.
Summary: In order for JSON to be, at all, competitive with XML/XSLT, there has to be a native means of transforming JSON data structures into strings (or DOM fragments), that can then be injected into an HTML document.
3) Upcoming standards imply its existance.
There are two upcoming standards that require some form of JavaScript object serialization (either explicitly, or implicitly).
The first, JSONRequest, (unsurprisingly, also from Douglas Crockford) is a means of securely transferring JSON data cross-domain. However, in order to implement this feature, some form of native JSON deserialization will be need to be implemented within the browser.
I know that Mozilla is considering implementing this feature, as is Microsoft, in Internet Explorer. Hopefully, this will mean that the two biggest browsers will have an implementation out quite soon.
The second is the new DOM Storage standard introduced by the WHATWG. While this feature does not require a form of JavaScript object serialization, it does only allow data to be stored as strings (and in order to make the most efficient use of that storage area, a form of object serialization will be needed).
However, the fact that two upcoming pseudo-standards need some form of object serialization requires us to re-examine the proposed API. It is imperative that it be rock-solid before being implemented in multiple platforms.
Here is the (rough) current API proposed by Crockford’s json.js:
Object.prototype.toJSONString
var foo = { test: true, sample: "string" };
foo.toJSONString();
>> '{"test":true,"sample":"string"}'
Array.prototype.toJSONString
var foo = [ true, "string", 5 ]; foo.toJSONString(); >> '[true,"string",5]'
Boolean.prototype.toJSONString
String.prototype.toJSONString
Number.prototype.toJSONString
5.toJSONString(); >> '5' "test".toJSONString(); >> '"test"' true.toJSONString(); >> 'true'
However, there’s still a lot of ambiguity in this particular API – especially when it comes to aspects of the language that aren’t perfectly serializable.
Function and RegExp
Note that the parseJSON method (rightfully) balks at extracting a Function or a RegExp:
"function(){}".parseJSON();
ERROR: parseJSON: undefined
"/foo/".parseJSON(); ERROR: parseJSON: undefined
While it happily serializes either using toJSONString() (with varying results):
function test(){}
test.toJSONString()
>> "{"prototype":{}}"
/foo/.toJSONString()
>> "{}"
null
Also, note that while parsing a serialized ‘null’ gives you the correct value back:
"null".parseJSON() >> null
it is unable to convert a null into its serialized form:
var foo = null; foo.toJSONString() ERROR: foo has no properties
A very important point needs to be made here: Some form of definition and specification should be made regarding this language addition. And soon. Even if it’s nothing other than defining that the above behavior is correct – that should be specified somewhere for all browser developers to follow.
Summary: The current, recommended, implementation of JSON parsing and serialization is harmful and slow. Additionally, upcoming standards imply that a native JSON (de-)serializer already exists. Therefore, browsers should be seriously looking at defining a standard for native JSON support, and upon completion implement it quickly and broadly.
To get the ball rolling, I recommend that you vote up the Mozilla ticket on the implementation, to try and get some critical eyes looking at this feature, making sure that it’s completely examined and thought through; and included in a browser as soon as possible.
Update: I located the specification that defines support for toJSONString/parseJSON in ECMAScript 4. This is great news. Now that the definition for this feature is happily moving along, it’s just time to get some implementations going!


Ric (March 6, 2007 at 9:15 pm)
I blogged about this on http://www.JSON.Com, but it seems your trackback did not catch it. Do you want me to repost my reponse here in your comments?
John Resig (March 6, 2007 at 9:42 pm)
@Ric – It appears as if trackbacks were disabled. Feel free to repost your response here.
Ric (March 6, 2007 at 10:08 pm)
First of all, I agree that jsON serialization should be put into the browsers, but then we will have what M$ thinks how it should be done vs. what everyone else does.
Keeping jsON “safe†seems to me to be of a security issue with Javascript. It involves overloading core script like the Array or Object constructor. Correct me if I am wrong, but doesn’t this involve a Cross-Site (XSS) or Man-In-The_Middle attack? This has nothing to do with jsON, except when using jsON Request is to grab data from multiple domains. (which Ajax with XmlHttp can not do) It simply is untrusted code. To deal with this untrusted code – why not follow the prototype pattern of loading js files using the library itself? That is – the first JS in a page is a loader object that can grab new javascript files, but then verify the new files do not muck around like changing core functions.
Using Douglas Crawford’s method for extracting the data is considered bad because he changes the behavior of Object.prototype. I agree this is usually bad, but I am sure we can tweak the code to make it behave.
John then describes how jsON is speedier than XML. Sort of. The big reason why people use json is because it IS JavaScript and is several orders of magnitude faster than raw XML. But if we want to _transform_ the json to do data tricks on it, then it is much slower than XSLT. This is because XSL is a standard that has been around for 10 years, while transforming JSON has not even been around 10 months. But JSONT will mature, and there are other, faster ways to transform jsON. Also there are trick you can do with json you simply can not do with XSLT as it currently is supported in all browsers
Anders (March 7, 2007 at 2:51 am)
I don’t see you the behavior with regards to functions and regexps is a problem. The to data types aren’t supported by JSON (see json.org) so it is no wonder. One feature of JSON is that it is language independent, so serialized functions wouldn’t make much sense.
That you can’t call methods on a null object seems to be just a tiny implementation detail. Use a wrapper like function t(v){var s=[v].toJSONString(); return s.substring(1,s.length-1);} if you really have the need for that (or use a functional interface instead of a oo-interface).
It seems that you would rather like access to spidermonkeys “uneval” function.
Wladimir Palant (March 7, 2007 at 5:25 am)
I think you are confusing things when you talk about security issues with JSON (and so does Kid666 in the blog post you are linking to – this is really about information disclosure, not XSS). The problem is that you can include a script tag on your web page that will load JSON from a different web page (e.g. GMail). If you redefine object/array prototypes before doing that you will be able to actually read the data. Of course if the script already contains an eval() call it makes your job even easier. So JSON encoded data generally has to be considered unsafe – regardless of how it is parsed. Either the parser is executed in its own domain and then you need an XSS vulnerability to infiltrate it – but if you found one you can read the data directly. Or the parser is executed in your domain and then you have to get the data first that you will feed it.
I heard of two solution to this problem. Either you don’t serve JSON with sensitive data under a fixed URL (e.g. require the session ID to be present in the URL) or you insert an endless loop before the JSON data. You can remove the loop before passing data to the parser, a web page loading the data with a script tag won’t be able to. A different parser on the other hand doesn’t solve anything.
Mark (March 7, 2007 at 8:59 am)
Sadly, Crockford’s json.js is not open source.
Ric (March 7, 2007 at 12:06 pm)
@Mark
json.Org IS Open – the link on json.Org specifically says “The open source code of a JSON parser and JSON stringifier is available.”
Mark (March 7, 2007 at 8:45 pm)
But have you actually read the license? It’s not a OSI-approved license, and it has a pretty alarming exception clause.
crud (March 7, 2007 at 11:18 pm)
Ric, what Mark is alluding to is the “don’t do evil” clause in the json.js license. OSI-compliant licenses are not allowed to discriminate user intent.
Mark (March 8, 2007 at 12:31 am)
crud is correct. Sorry I was in a hurry earlier and couldn’t fully explain this.
Rather than reusing an existing OSI-approved license, Douglas Crockford has decided to create his own. His “JSON license”, which explicitly covers json.js, comes encumbered with a rather alarming exception: “The Software shall be used for Good, not Evil.”
Funny, right? Ha ha. I love jokes in licenses. They ring about as hollow as bomb jokes in airports. We can all have a good laugh and get on with the business of writing code.
Except for one thing: he’s not kidding. He has publicly confirmed that it’s not a joke, saying “If someone is unable to assert that they are not using it for Evil, then I don’t want them using my software.” ( source: http://simonwillison.net/2005/Dec/16/json/#c32497 )
That Crockford, he’s a funny guy. Invite him to parties. Don’t use his code.
zimbatm (March 8, 2007 at 3:49 am)
Some thoughts
In point 1, you say that adding methods to Object.prototype is considered harmful. But in point 3 you seem to be happy with the new Object.prototype.toJSONString method. Does making that method native circumvent the problems considered in point 1 ?
John Resig (March 8, 2007 at 4:07 am)
@zimbatm: That’s correct (I should’ve specified that in the post). For example, all objects have a .toString() method. You can’t iterate over it, even though it exists (which is exactly how a .toJSONString() method should work, too).
Robert O'Callahan (March 8, 2007 at 4:47 am)
Why do you say that “Data Records By Time” shows a failure to scale? It looks like things are mostly scaling linearly. Your graph looks exponential because you chose a log scale for your x-axis…
Dao (March 8, 2007 at 5:19 am)
Besides uneval(), SpiderMonkey also features .toSource().
John Resig (March 8, 2007 at 10:22 am)
@Anders: “I don’t see you the behavior with regards to functions and regexps is a problem.” It’s not, necessarily, a problem – but it’s just something to consider. Obviously, people may treat Functions or RegExps like objects (extending them with their own properties), so it’s probably a good idea to make an honest attempt at serializing them. However, why is the extra prototype property provided for the Function serialization, and not the RegExp one? Although, it seems as if some work is already being done (in the ES4 spec) to solve this.
@Wladimir: “A different parser on the other hand doesn’t solve anything.” A different JavaScript-based parser, no. But a parser that’s written in C and embedded in the browser is another issue entirely. The browser will be able to circumvent most of the trickery that a malicious user would be able to implement. However, JavaScript Arrays, in general, may still be vulnerable to this exploit – but that’s another issue at play here.
@Robert: I didn’t intend for it to sound like that – only that “The recommend method of deserialization doesn’t scale [as well as JSONP].” Presumably since JSONP’s JavaScript parser/serializer is located within the browser core itself, rather than implemented purely in JavaScript. Simply: By removing the need to have a pure-JavaScript JSON parser, you lose a lot of overhead and computation time.
Kevin H (March 8, 2007 at 3:52 pm)
John,
Regarding your Side Discussion, try running the TrimPath Javascript Templates instead of jsont. Using 200 data records, on my PC the XML+XSLT test takes 0.0911s/run, the jsont test takes 0.20501s/run, and the Javascript Templates test beats them both, taking 0.04515s/run.
Lenny (March 11, 2007 at 7:42 pm)
Mark, take a look at json.js. It’s public domain. At one point it had a restrictive license, but the latest public domain version is timestamped the day before your first comment. Also, a modified version of Crockford’s code is used in Firefox under the GPL to parse search suggestions.
rajiv (April 13, 2007 at 1:01 am)
i want to post my JSON parser for C++ on JSON.org how do I do it?
John Hann (May 3, 2007 at 11:43 am)
In addition, we need to add a native date literal format to JSON (and Javascript). Passing dates as strings to disparate systems has started becoming a major headache. Douglas Crockford suggests using a callback function to detect and parse dates (because his validation regexp fails on the text, new Date()), but why can’t we just have a native literal format? Javascript 1.6 already supports native literals for:
– XML: var myxml = text content;
– Object: var myObj = {prop1: value1, prop2: value2};
– Array: var myArray = [item1, item2];
– RegExp: var myRx = /foo\d+/ig;
and of course, Booleans, numbers, and strings. Why not dates?
Date?: var myDate = #2007-05-02 14:30:00-4:00#; // or something similar
Micon Frink (May 16, 2007 at 4:54 am)
John,
Date literals would be an incredible addition for the sake of JSON!!! This is something that should have been their from the beginning. Your suggested implementation is not bad! have you suggested it to standards bodies?
All,
I disagree with further prototyping which can be problematic on multiple platforms. I think a very simple JSONencode() and JSONdecode() would better serve the purposes like what is found in PHP’s PECL implementation for JSON. (which still needs work BTW doesn’t read basic JSON from del.icio.us!!!) While JavaScript’s great strength is it’s power to prototype it’s also a great weakness. By keeping all the JSON code in fewer functions we are able to keep the code base small and eschew obfuscating the implementation in multiple prototypes.
Douglas Crockford (August 7, 2007 at 2:38 pm)
The json.js library is Public Domain.
alek (September 5, 2007 at 9:42 am)
vote added