Firefox 3.0a3 has just been released, including a number of changes and new features. A list of some of the major new features can be found on the Mozilla site.
However, there are a number of changes and additions that are particularly relevant to JavaScript developers, in particular, that I would like to take the opportunity to highlight.
(This reminds me, if you don’t yet subscribe to The Burning Edge, I highly recommend it; it does weekly recaps of the changes that have gone into Firefox, highlighting important features or bug fixes.)
clientLeft and clientTop are now supported.
These two properties have long been a part of Internet Explorer and are now making their way into Firefox. This is to complement the clientHeight and clientWidth properties that already exist.
What these properties provide can be best described through a diagram; luckily, the Mozilla Developers Wiki already has some nice ones, so I’m just going to repost them here:


While they’re not terribly exciting properties to have, it’s good to finally have a full set to work with.
You can hide cookies from scripts.
This one might seem rather innocuous, at first, but is a huge win in the Cross-Site Scripting (XSS) war. More often, than not, the true reward for performing some form of XSS is snagging valuable session information from a user’s cookies. This relies on the fact that client-side JavaScript is able to access all of the cookies set and sent by the server. However, this is no longer the case. An HttpOnly flag, proposed and implemented by Microsoft in Internet Explorer 6, is now available in Firefox 3.0. A server, when setting a new cookie, can include the HttpOnly flag and know that the JavaScript won’t have access to it. Of course, this isn’t completely effective until all browsers have this property implemented, but it’s certainly a step in the right direction.
Example:
Set-Cookie: sessionid=1234567; domain=mozilla.org; HttpOnly
You can mark resources as being available offline.
This is an interesting feature that doesn’t, yet, have a specification-home (although, some suspect that it’ll be adopted by the WHATWG). It provides the ability, for the user, to specify individual resources for special caching, should the browser move into offline mode.
In my personal tests, I was able to get it such that an XML file, specified exclusively as an “Offline Resource”, was able to be retrieved, using an XMLHttpRequest, even while being disconnected from the Internet. You can view a demo here (Make sure that you’re running, at least Firefox 3.0a3.) The relevant code, from the test page, is as follows:
...
<head>
<link rel="offline-resource" href="test.xml"/>
<title>Offline Resource Test</title>
<script>
window.onload = function(){
var button = document.getElementById("button");
button.onclick = function(){
var xhr = new XMLHttpRequest();
xhr.open( "GET", "test.xml", true );
xhr.onreadystatechange = function(){
if ( xhr.readyState == 4 ) {
alert( xhr.responseXML
.documentElement.firstChild.textContent );
}
};
xhr.send( null );
};
};
</script>
</head>
...
The important line being:
<link rel="offline-resource" href="test.xml"/>
which allows you to make the browser pre-cache the test.xml file, for later use. This can be done with a number of resource files (CSS, Images, etc.) and is not just limited to pieces of data; which makes it immensely useful. Mark Finkle has some more details on his blog.
RegExps have a new /y flag.
This feature has trickled down to us from the upcoming ECMAScript 4 (JavaScript 2) specification. More information about /y can be found there. In a nutshell: It allows you to start a regular expression leaving off where the last match, of the last expression, ended. In Perl, this is similar to placing a \G at the beginning of your regular expression.
JavaScript: Remove the first instance of ‘dog’ after the first instance of ‘cat’.
var str = "mouse dog mouse cat dog"; str.match(/cat/); str = str.replace(/ dog/y, ""); >> str == "mouse dog mouse cat"
Perl:
my $str = "mouse dog mouse cat dog"; $str =~ /cat/; $str =~ s/\G dog//; >> str eq "mouse dog mouse cat"
You can create new nodes in DOM Inspector.
A minor, but useful and important, feature addition to the built-in Firefox DOM Inspector. This new feature is perfect for performing additional testing on live pages, to see their effect. A quick demonstration of how it works:
There’s a new menu option allowing you to insert a node in relation to the selected node:
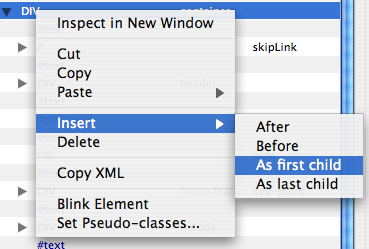
Once selected, you can then insert an element (with namespace) or a text node:
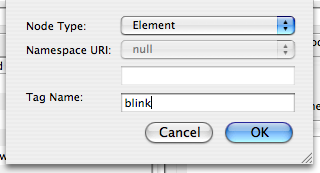
Giving you a nice new result:

How to try all of this at home!
Mozilla provides full builds of the latest bleeding-edge installs. You can find them linked to the individual Burning Edge blog posts, or at the following URL:
http://ftp.mozilla.org/pub/mozilla.org/firefox/nightly/latest-trunk/


Jordan Sissel (March 27, 2007 at 3:31 pm)
re: hiding cookies from javascript –
So you can’t view them via document.cookies, right? But what if the XSS sends an XHR request and views the cookie headers, which will have the cookies in it?
John Resig (March 27, 2007 at 4:08 pm)
@Jordan: That’s a good question. I’m going to go out on a limb and assume that you won’t be able to access them there, either, but I don’t know that for a fact. I’ll have to setup a test environment to look at that further.
carmen (March 31, 2007 at 8:32 pm)
cool. wake me up when glitz works with openGL accel, so i can switch back to linux and see if ctrl-+ no longer freezes up the browser for 5 seconds..
carmen (March 31, 2007 at 8:32 pm)
how are the other browser vendors handling the transition to ES4?
i mean, the JS 1.6 and 1.7 stuff – does that work in other browsers? it sure seems like we’re getting a 1.8 and 1.9 before 2.0
Kharilaos (July 9, 2007 at 11:07 am)
Interesting…
Stratos (July 10, 2007 at 12:33 am)
Nice
Yiannos (July 10, 2007 at 12:57 am)
Nice!
Marinos (July 10, 2007 at 5:21 am)
interesting
Stefanos (July 15, 2007 at 5:44 am)
interesting
Polyvios (August 29, 2007 at 2:10 pm)
Cool.
FreeSEOAds (September 20, 2007 at 4:26 am)
It’s very interesting article. Thanks.
berry (October 4, 2007 at 6:08 am)
Thanks for the info. Very Good article. I entirely agree with you. I am respect your blog.