Mark Finkle suggested that I do some speed testing, now that a native implementation of getElementsByClassName has landed in the Mozilla trunk (destined for Firefox 3).
So I went around and dug up all of the different, existing, implementations that I could find. Currently, implementations fall into one of three categories (with some straddling more than one):
- Pure DOM
This usually involves a calls to.getElementsByClassName("*")and traversing through all matched elements, analyzing each element’sclassNameattribute along the way. Generally, the fastest method is to use a pre-compiled RegExp to test the value of the className attribute. - DOM Tree Walker
Is a less-popular means of traversing DOM documents by setting some simple parameters, as specified by the DOM Level 2 Spec. For example, you could traverse through all text nodes in a document (something that you can’t easily do in any other way). - XPath
The most recent technique, to be popularized, was the use of XPath to find elements by classname. The implementation is generally simple: Building a single expressions and letting the XPath engine traverse through the document, finding all the relevant elements.
I’ve chosen some implementations that were representative of each of these techniques.
Tree Walker
An implementation using the DOM Level 2 Tree Walker methods. Builds a generic filter function and traverses through all elements.
document.getElementsByClass = function(needle) {
function acceptNode(node) {
if (node.hasAttribute("class")) {
var c = " " + node.className + " ";
if (c.indexOf(" " + needle + " ") != -1)
return NodeFilter.FILTER_ACCEPT;
}
return NodeFilter.FILTER_SKIP;
}
var treeWalker = document.createTreeWalker(document.documentElement,
NodeFilter.SHOW_ELEMENT, acceptNode, true);
var outArray = new Array();
if (treeWalker) {
var node = treeWalker.nextNode();
while (node) {
outArray.push(node);
node = treeWalker.nextNode();
}
}
return outArray;
}
The Ultimate getElementsByClassName
Uses a pure DOM implementation, tries to make some optimizations for Internet Explorer.
function getElementsByClassName(oElm, strTagName, strClassName){
var arrElements = (strTagName == "*" && oElm.all)? oElm.all :
oElm.getElementsByTagName(strTagName);
var arrReturnElements = new Array();
strClassName = strClassName.replace(/\-/g, "\\-");
var oRegExp = new RegExp("(^|\\s)" + strClassName + "(\\s|$)");
var oElement;
for(var i=0; i<arrElements.length; i++){
oElement = arrElements[i];
if(oRegExp.test(oElement.className)){
arrReturnElements.push(oElement);
}
}
return (arrReturnElements)
}[/js]
<h3><a href="http://www.dustindiaz.com/getelementsbyclass">Dustin Diaz's getElementsByClass</a></h3>
A pure DOM implementation, caches the regexp, and is generally quite simple and easy to use.
[js]function getElementsByClass(searchClass,node,tag) {
var classElements = new Array();
if ( node == null )
node = document;
if ( tag == null )
tag = '*';
var els = node.getElementsByTagName(tag);
var elsLen = els.length;
var pattern = new RegExp("(^|\\s)"+searchClass+"(\\s|$)");
for (i = 0, j = 0; i < elsLen; i++) {
if ( pattern.test(els[i].className) ) {
classElements[j] = els[i];
j++;
}
}
return classElements;
}[/js]
<h3><a href="http://prototypejs.org/">Prototype 1.5.0</a> (XPath)</h3>
Mixes an XPath and DOM implementation; using XPath wherever possible.
[js]document.getElementsByClassName = function(className, parentElement) {
if (Prototype.BrowserFeatures.XPath) {
var q = ".//*[contains(concat(' ', @class, ' '), ' " + className + " ')]";
return document._getElementsByXPath(q, parentElement);
} else {
var children = ($(parentElement) || document.body).getElementsByTagName('*');
var elements = [], child;
for (var i = 0, length = children.length; i < length; i++) {
child = children[i];
if (Element.hasClassName(child, className))
elements.push(Element.extend(child));
}
return elements;
}
};[/js]
<h3><a href="https://johnresig.com/blog/getelementsbyclassname-in-firefox-3/">Native, Firefox 3</a></h3>
A native implementation, written in C++; is a part of the current CVS version of Firefox, will be included in Firefox 3.
[js]document.getElementsByClassName
The Speed Results
For the speed tests I copied the Yahoo homepage into a single HTML file and used that as the test bed. They make good use of class names (both single and multiple) and is a considerably large file with lots of elements to consider.
You can find the test files, for each of the implementations, here:
https://johnresig.com/apps/classname/
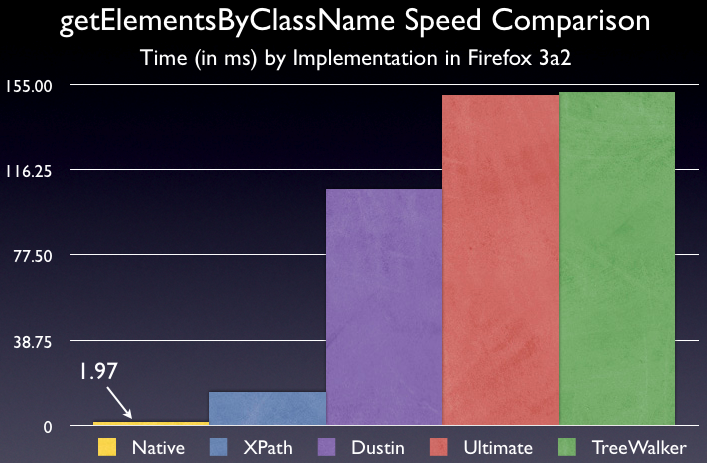
Note: “XPath” is just Prototype’s implementation.
From these figures we can see that the native implementation of getElementsByClassName, in Firefox 3, is a full 8x faster than the XPath implementation. Additionally, it’s a stunning 77x faster than the fastest DOM implementation.
Note: These numbers have been revised from what was originally posted as the lazy-loading nature of
document.getElementsByClassNamewasn’t taken into account. The resulting arrays are completely looped-through now, making sure that all elements are accounted for.
Currently, Prototype has the best general-use implementation: Use XPath selectors wherever possible, fall back to fast DOM parsing.
Interestingly, only Prototype actually tries to implement the document.getElementsByClassName interface (all others do one-off names). However, Prototype doesn’t check to see if the document.getElementsByClassName property already exists, and completely overwrites the, incredibly fast, native implementation that Firefox 3 provides (oops!).
In all, the results are quite astounding. The native implementation is absolutely much faster than anything I could’ve imagined. It completely decimates all the other pieces of code. I can’t wait until this hits the general public – users will, absolutely, feel a significant increase in speed.


{kind=link}
Anthony Ettinger (March 8, 2007 at 5:17 am)
Thanks for these 3 Pro Techniques — I’m digging the book by the way, just read 2 chapters tonight (Events + JS/CSS)…looking forward to rewriting some code tomorrow.
I’m surpised XPath is that much of an improvement — any idea how well supported it is?
I ran across the problem in IE with ‘*’ selector and getElementsByTagName(‘*’) on Dustin’s version, and opted to default to the body tag as the starting node.
It’s great to see someone out there doing speed comparisons on new functionality as it becomes available.
glandium (March 8, 2007 at 7:53 am)
That just means something we’ve all known for a long time: “Dynamic HTML” is slow. Damn slow. And it’s also the reason “Dynamic HTML” is only growing now, with AJAX and its friends: we finally have computers fast enough that it doesn’t look “that” slow.
Michael Kaply (March 8, 2007 at 9:40 am)
What about getElementsByAttributeName/Value?
John Resig (March 8, 2007 at 10:10 am)
@Anthony: If I remember correctly, XPath is supported well in Firefox and Opera – and the upcoming new release of Safari (which doesn’t help us yet).
What issue are you having with .getElementsByTagName(“*”)? Do you have comments in your code? (IE returns comments with a tagName of “!” from getElementsByTagName.)
@Michael: I’m not sure what you’re referring to, specifically. There’s a
getElementsByName; but that isn’t as popular (since most users don’t select elements by name). There are some customgetElementsByAttrimplementations floating around, but none of them are standard, nor part of any browser (as far as I know).Masklinn (March 8, 2007 at 10:48 am)
> If I remember correctly, XPath is supported well in Firefox and Opera – and the upcoming new release of Safari (which doesn’t help us yet).
As far as I know you’re right on the money.
On a side note, would it be possible that you re-run your tests on Opera 9.10, Webkit trunk (the upcoming Safari 3) and IE6/IE7? From past personal tests i remember that they had widely different raw speeds (with Opera being a speed demon at JS stuff), but also widely different behaviours faced with the various implementations (except that XPath was always the winner if the browser handled it)
Giorgio Maone (March 8, 2007 at 10:50 am)
John, I guess mkaply refers to the XULDocument::getElementsByAttribute() method. I know JQuery lives content-land, but now that you’re in charge of FUEL you should accept Chrome in your life ;)
Jesse Ruderman (March 8, 2007 at 11:59 am)
Does your speed test include looping over the returned array / nsContentList? Based on skimming the patch it looks like calling document.getElementsByClassName only sets up a data structure without walking the document.
Jesse Ruderman (March 8, 2007 at 12:02 pm)
Please don’t assume that just because a native implementation of a given feature is faster than existing JavaScript implementations running against the current JavaScript engine and DOM implementation, it makes sense to add the new implementation to Gecko. Once Tamarin lands, some of these native implementations will become unneeded bloat.
Boris (March 8, 2007 at 12:23 pm)
You’re comparing apples and oranges, as Jesse says. The native implementation doesn’t actually do any DOM walking until you ask it for something from the list. I suggest getting the “length” property of the list in that test to make this a fairer comparison.
With that said, there’s another important difference here: the native impl is live, so if you hold on to it it’ll automatically update (as cheaply as it can) when your DOM mutates. Not sure how useful that is in practice, of course.
John Resig (March 8, 2007 at 1:35 pm)
@Jesse and Boris: You made a good point about the lazy-loading nature of the getElementsByClassName implementation, so I adjusted the test suite and re-ran everything. By adding a .length to the query, the time for native implementation was raised from 0.25 to 0.96ms. I added in an extra loop, just to make completely sure, and the number was raised to 1.97ms. All implementations felt a similar increase in duration, although it was most represented by the native implementation (since adding a simple loop effectively halves its apparent speed).
@Jesse: “Once Tamarin lands, some of these native implementations will become unneeded bloat.” I somehow doubt that even the most-optimized JavaScript (even running on top of Tamarin) will be able to outperform a C++-based implementation of a commonly-needed DOM method. While the gap will be definitely be reduced in Firefox, not all browsers are upgrading their JavaScript engines significantly (whereas adding a commonly used DOM method is a much more tangible goal that more browser vendors can get behind). Additionally, I would barely consider this to be a bloated feature – it’s been requested so much by web developers that the WHATWG felt compelled to include it in their HTML5 spec. I completely agree with their decision – and as the numbers show, it’s going to be a very useful addition at that.
Jeremy Sisson (March 8, 2007 at 1:55 pm)
I would be interested in seeing a breakdown of these results run across a selection of browsers (FF, Safari, IE6, IE7, etc). I have tried using getElementsByClassName for a while on one particular project that involved a large form, but I had to remove it because it would take way to long in IE6.
I appreciate that Firefox is getting a native implementation, but we usually have to develop based on low performance in IE, and that means avoiding getElementsByClassName for now.
Jesse Ruderman (March 8, 2007 at 4:47 pm)
FWIW, you might be interested in bug 320020, a hang caused by a script on my.yahoo.com (!) trying to implement getElementsByClass through recursive tree-walking.
Axel Hecht (March 9, 2007 at 4:54 am)
A comment on the XPath implementation, it does a
.//*
which may or may not be outperformed significantly by
descendent::*
We optimize the first to the latter in some version of Firefox now, IIRC, but we didn’t for the longest time, and the two implementations scale differently.
James Chao (March 9, 2007 at 2:59 pm)
Good work, thanks for this great analysis!
I want to echo the suggestion made by others about getting the results on IE 6/7 since IE is still the dominantly popular browser in the wider audience (unfortunately).
Also, I tried doing some testing of my own and found that testing against className as a DOM property was slower than testing again a random attribute (e.g., ‘handle’). So in our development we opted to use getElementsByHandle and that proved to be slightly faster than using className with the addition benefit of providing code separation between the programmers and the designers. Is there anyone else out there that’s tried this approach?
James Chao (March 9, 2007 at 3:05 pm)
Also, our implementation also includes the (optional) parent node and the tag name arguments, which does speed things up a bit. And instead of using a regular expression, we are just using a simple indexOf() and that seems to improve the performance as well.
Jörn Zaefferer (March 10, 2007 at 8:04 am)
I think “This usually involves a calls to .getElementsByClassName(“*”)” in the Pure DOM paragraph should be “This usually involves a calls to .getElementsByTagName(“*”)”.
James Chao: Matching classes via indexOf() seems to be a bit error-prone. To correctly match the class, there must be nothing or whitespace in front and after the class. Taking that into account with indexOf() doesn’t seem to be worth it.
Laurens Holst (March 11, 2007 at 3:01 am)
@Michael: You can do getElementsByClassName(‘[attrname=value]’), right?
David M. Cooke (March 11, 2007 at 10:30 pm)
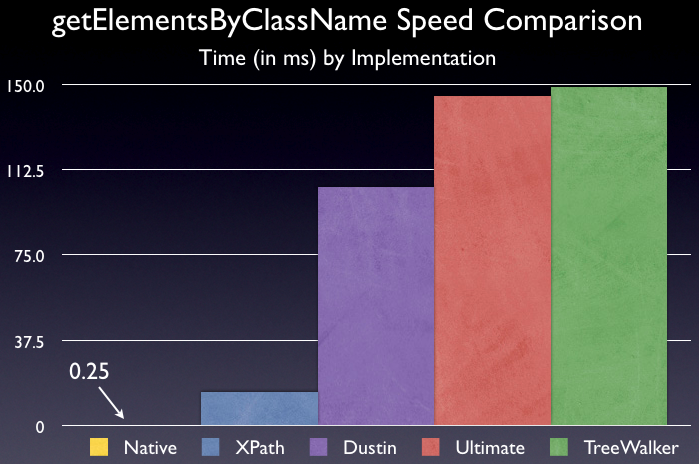
I’ve run speed comparisons on my MacBook for Camino, WebKit, Safari, and Opera. The results are on my blog, at http://blog.isobaric.ca/2007/03/getelementsbyclassname-speed-comparison.html
The essential result is that Dustin’s getElementsByClassName is the best on the non-Gecko browsers, and treewalker is awful (doesn’t even finish on Opera).
RichB (March 13, 2007 at 4:13 pm)
Some of the implementations in your post are incorrect. The HTML spec defines the class name as being whitespace delimited. Some of your example functions assume space delimited. This will fail when the classnames are delimited by tabs. Also, is there a reason for writing your treewalker loop as you did and not using walker.currentNode? Is it faster?
Andrew Dupont (March 28, 2007 at 1:16 pm)
John, I’ll make sure that future versions of Prototype define document.getElementsByClassName only if it does not already exist. (And I suppose we’ll have to move our node instance method from “Element.Methods” to “Element.Methods.Simulated” (the latter copies methods over only if they don’t exist already). Thanks for bringing this up.
Anthony Ettinger (May 7, 2007 at 6:56 pm)
@John Resig Regarding the tag = ‘*’; but I found it in IE 5.5…probably not all that important these days.
But I defaulted to document.all:
if (!tag) tag = ‘*’;
var allElems = node.getElementsByTagName(tag) || document.all; //IE5.5 ‘*’ fix
Garrett (September 9, 2007 at 5:03 pm)
John,
Great to see this is going in to Firefox.
A few comments on the code and test:
When you add a function to a COM object, you expose a memory leak problem with IE.
You really should not do this. Calling delete won’t work in IE either. You can’t call delete on an expando (in JScript). (This bad approach/idea has existed prototype for a while now.)
onunload = function() {delete document.getElementsByClass;
};
You could set it to null.
Why not instead write a
getElementsByClassfunction that checks for native support (document.getElementsByClassName)? If supported, use that. Otherwise, use a hand-rolled one.Also, I’d like to point out, you quoted:
“A pure DOM implementation, caches the regexp, and is generally quite simple and easy to use.”
Implementations may cache RegExp objects, but are not required to do so. There is nothing in ECMA= 262 that indicates the contrary. The RegExp instance might be cached in some Hosts, however, claiming that this will occur is not true.
After the function is executed, the
RegExpis available for garbage collection.For this reason, I created (back in 2001) a way to cache tokenized expressions. (I am in no way trying to discredit Dustin’s own method, which uses the same regexp). It’s still it on my site, which
I’ll admit is quite old, and I won’t link to it here. Seek and ye shall find.
Now if you meant: the
RegExpis created before theforloop, well, that is needless to say; the code is right there. Creating the regexp inside the loops body would be quite obviously inefficient.I also want to mention that the HTML 5
getElementsByClassNameis limited.Method
getElementsByClassNameworks on Document level, not node level. You can’tgetElementsByClassNameon a fragment in Abstract view and you can’t call it on any old node, which mostgetElementsByClassfunctions allow.Garrett (September 9, 2007 at 8:53 pm)
The IE Memory Leaks:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/IETechCol/dnwebgen/ie_leak_patterns.asp
adv88 (September 20, 2007 at 4:24 am)
Thank you for your reliable post, that’s what i was searching for.
tonya harding (October 4, 2007 at 6:11 am)
Thanks for the great tips!
A must read for all the users out there!